
محاسبات موازی
محاسبات موازی نوعی از محاسبات است که در آن بسیاری از محاسبات یا فرآیندها به طور همزمان انجام می شود.[1] مشکلات بزرگ را اغلب می توان به مشکلات کوچکتر تقسیم کرد که در همان زمان می توان آنها را حل کرد. چندین شکل مختلف از محاسبات موازی وجود دارد: سطح بیت، سطح دستورالعمل، داده و موازی کاری. موازیسازی مدتهاست که در محاسبات با کارایی بالا استفاده میشود، اما به دلیل محدودیتهای فیزیکی که از مقیاسبندی فرکانس جلوگیری میکند، توجه گستردهتری به دست آورده است.[2] از آنجایی که مصرف برق (و در نتیجه تولید گرما) توسط رایانهها در سالهای اخیر به یک نگرانی تبدیل شده است، [3] محاسبات موازی به الگوی غالب در معماری کامپیوتر، عمدتاً به شکل پردازندههای چند هستهای تبدیل شده است.
محاسبات موازی ارتباط نزدیکی با محاسبات همزمان دارد – آنها اغلب با هم استفاده می شوند، و اغلب با هم ترکیب می شوند، اگرچه این دو متمایز هستند: ممکن است موازی بودن بدون همزمانی (مانند موازی سازی سطح بیت) و همزمانی بدون موازی (مانند چند وظیفه ای) وجود داشته باشد. با اشتراک گذاری در یک CPU تک هسته ای).[5][6] در محاسبات موازی، یک کار محاسباتی معمولاً به چند کار فرعی، اغلب بسیار، بسیار مشابه تقسیم میشود که میتوانند بهطور مستقل پردازش شوند و نتایج آنها پس از تکمیل، ترکیب میشوند. در مقابل، در محاسبات همزمان، فرآیندهای مختلف اغلب به وظایف مرتبط نمی پردازند. هنگامی که آنها انجام می دهند، همانطور که در محاسبات توزیع شده معمول است، وظایف جداگانه ممکن است ماهیت متفاوتی داشته باشند و اغلب به برخی ارتباطات بین فرآیندی در طول اجرا نیاز دارند.
رایانههای موازی را میتوان تقریباً بر اساس سطحی که سختافزار از موازیسازی پشتیبانی میکند طبقهبندی کرد، رایانههای چند هستهای و چند پردازندهای دارای عناصر پردازشی متعدد در یک دستگاه واحد هستند، در حالی که خوشهها، MPP ها و شبکهها از چندین رایانه برای کار بر روی یک دستگاه استفاده میکنند. وظیفه. معماریهای موازی تخصصی کامپیوتر گاهی در کنار پردازندههای سنتی برای تسریع وظایف خاص مورد استفاده قرار میگیرند.
در برخی موارد موازیسازی برای برنامهنویس شفاف است، مانند موازیسازی سطح بیت یا سطح دستورالعمل، اما الگوریتمهای موازی صریح، بهویژه آنهایی که از همزمانی استفاده میکنند، نوشتن دشوارتر از الگوریتمهای متوالی است، [7] زیرا همزمانی چندین الگوریتم جدید معرفی میکند. کلاس هایی از اشکالات نرم افزاری بالقوه، که شرایط مسابقه رایج ترین است. ارتباط و همگام سازی بین وظایف فرعی مختلف معمولاً برخی از بزرگترین موانع برای دستیابی به عملکرد بهینه برنامه موازی است.
یک حد بالای نظری در افزایش سرعت یک برنامه واحد در نتیجه موازی سازی توسط قانون امدال ارائه شده است.
به طور سنتی، نرم افزار کامپیوتری برای محاسبات سریال نوشته شده است. برای حل یک مسئله، یک الگوریتم به عنوان یک جریان سریالی از دستورالعمل ها ساخته و پیاده سازی می شود. این دستورالعمل ها بر روی یک واحد پردازش مرکزی در یک کامپیوتر اجرا می شوند. فقط یک دستور ممکن است در یک زمان اجرا شود – پس از اتمام آن دستورالعمل، دستور بعدی اجرا می شود.[8]
از سوی دیگر، محاسبات موازی، از چندین عنصر پردازشی به طور همزمان برای حل یک مشکل استفاده می کند. این کار با تقسیم مسئله به بخشهای مستقل انجام میشود تا هر عنصر پردازش بتواند بخشی از الگوریتم خود را به طور همزمان با بقیه اجرا کند. عناصر پردازشی می توانند متنوع باشند و شامل منابعی مانند یک کامپیوتر منفرد با چندین پردازنده، چندین کامپیوتر شبکه ای، سخت افزار تخصصی یا هر ترکیبی از موارد فوق می شوند.[8] محاسبات موازی تاریخی برای محاسبات علمی و شبیهسازی مسائل علمی بهویژه در علوم طبیعی و مهندسی مانند هواشناسی استفاده میشد. این امر منجر به طراحی سخت افزار و نرم افزار موازی و همچنین محاسبات با کارایی بالا شد.[9]
← اجاره ابر رایانه →
مقیاس فرکانس دلیل اصلی بهبود عملکرد کامپیوتر از اواسط دهه 1980 تا سال 2004 بود. زمان اجرا یک برنامه برابر است با تعداد دستورالعمل ضرب در میانگین زمان هر دستورالعمل. ثابت نگه داشتن سایر موارد، افزایش فرکانس ساعت، میانگین زمان لازم برای اجرای یک دستورالعمل را کاهش می دهد. بنابراین افزایش فرکانس زمان اجرا را برای همه برنامه های محاسباتی کاهش می دهد.[10] با این حال، توان مصرفی P توسط یک تراشه با معادله P = C × V 2 × F ارائه می شود، که در آن C ظرفیت سوئیچینگ در هر سیکل ساعت (متناسب با تعداد ترانزیستورهایی که ورودی آنها تغییر می کند)، V ولتاژ است، و F است. فرکانس پردازنده (چرخه در ثانیه) است.[11] افزایش فرکانس باعث افزایش توان مصرفی در یک پردازنده می شود. افزایش مصرف انرژی پردازنده در نهایت منجر به لغو پردازنده های Tejas و Jayhawk توسط اینتل در 8 می 2004 شد، که عموماً به عنوان پایان مقیاس فرکانس به عنوان الگوی معماری غالب رایانه ذکر می شود.[12]
برای مقابله با مشکل مصرف برق و گرمای بیش از حد واحد پردازش مرکزی اصلی (CPU یا پردازنده) تولید کنندگان شروع به تولید پردازنده های کم مصرف با چندین هسته کردند. هسته واحد محاسباتی پردازنده است و در پردازندههای چند هستهای هر هسته مستقل است و میتواند به طور همزمان به حافظه مشابهی دسترسی داشته باشد. پردازنده های چند هسته ای محاسبات موازی را به رایانه های رومیزی آورده اند. بنابراین موازی سازی برنامه های سریال به یک وظیفه اصلی برنامه نویسی تبدیل شده است. در سال 2012، پردازندههای چهار هستهای برای رایانههای رومیزی استاندارد شدند، در حالی که سرورها دارای پردازندههای 10 و 12 هستهای هستند. از قانون مور می توان پیش بینی کرد که تعداد هسته های هر پردازنده هر 18 تا 24 ماه دو برابر می شود. این می تواند به این معنی باشد که پس از سال 2020 یک پردازنده معمولی ده ها یا صدها هسته خواهد داشت.[13]
یک سیستم عامل می تواند اطمینان حاصل کند که وظایف مختلف و برنامه های کاربر به صورت موازی بر روی هسته های موجود اجرا می شوند. با این حال، برای اینکه یک برنامه نرم افزار سریال از معماری چند هسته ای استفاده کامل کند، برنامه نویس باید کد را بازسازی و موازی کند. افزایش سرعت اجرای نرمافزار کاربردی دیگر از طریق مقیاسبندی فرکانس به دست نمیآید، در عوض برنامهنویسان باید کد نرمافزار خود را موازیسازی کنند تا از قدرت محاسباتی فزاینده معماریهای چند هستهای استفاده کنند.[14]
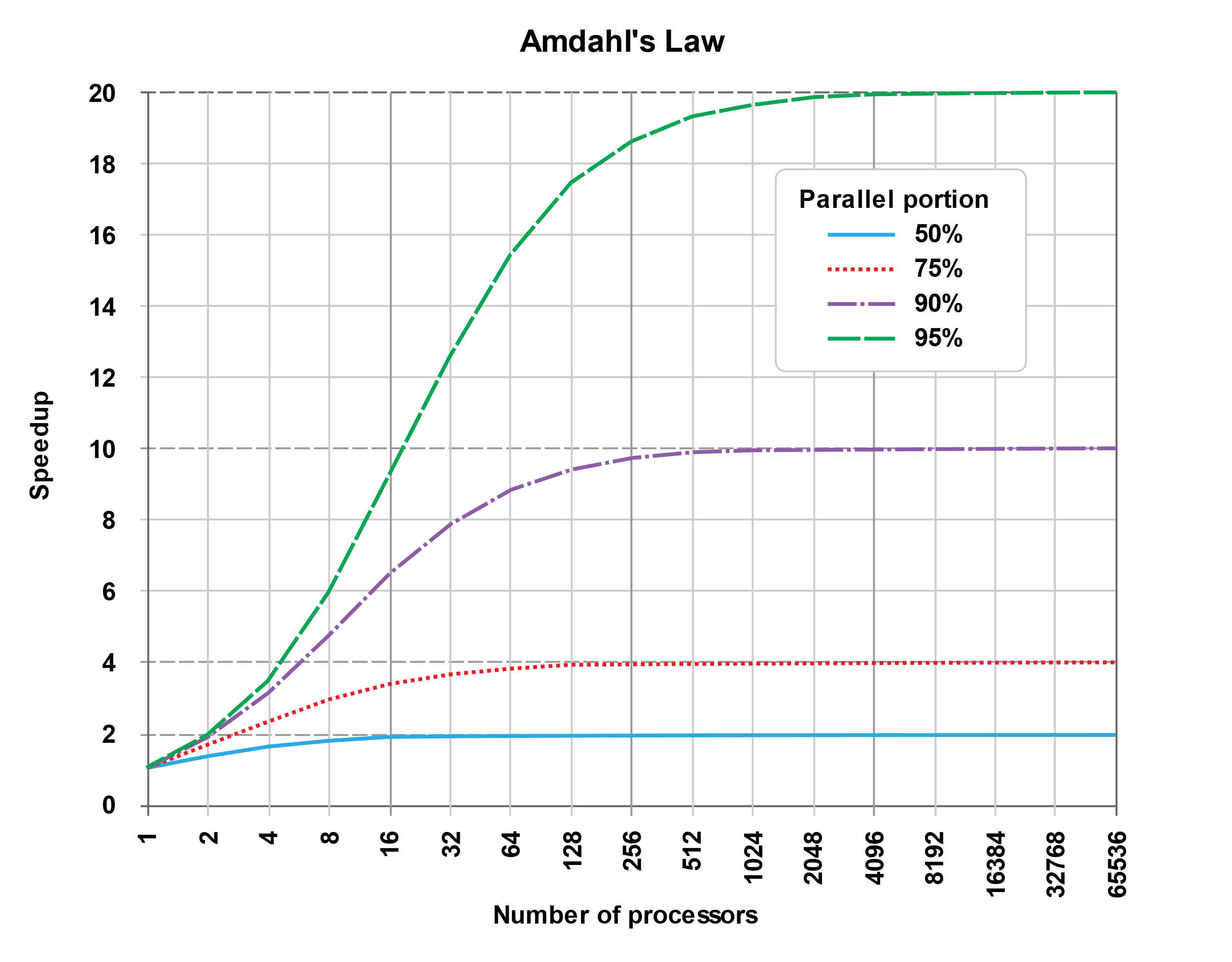
قانون امدال و قانون گوستافسون
نمایش گرافیکی قانون امدال. سرعت یک برنامه از موازی سازی به مقداری از برنامه که می تواند موازی شود محدود می شود. به عنوان مثال، اگر بتوان 90% برنامه را موازی کرد، حداکثر سرعت تئوری با استفاده از محاسبات موازی 10 برابر خواهد بود بدون توجه به اینکه چند پردازنده استفاده می شود.
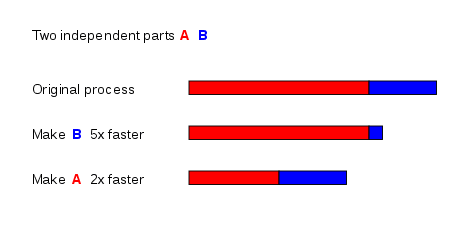
فرض کنید که یک کار دارای دو بخش مستقل A و B است. بخش B تقریباً 25٪ از زمان کل محاسبه را می گیرد. با کار بسیار سخت، ممکن است فرد بتواند این قسمت را 5 برابر سریعتر بسازد، اما این تنها زمان کل محاسبات را کمی کاهش می دهد. در مقابل، ممکن است نیاز باشد که کار کمتری انجام شود تا قسمت A دو برابر سریعتر باشد. این امر محاسبات را بسیار سریعتر از بهینهسازی بخش B میکند، حتی اگر سرعت بخش B با نسبت بیشتر باشد (5 برابر در مقابل 2 برابر).
در حالت بهینه، افزایش سرعت حاصل از موازی سازی خطی خواهد بود – دوبرابر کردن تعداد عناصر پردازش باید زمان اجرا را به نصف کاهش دهد و دوبرابر کردن آن برای بار دوم باید دوباره زمان اجرا را به نصف کاهش دهد. با این حال، تعداد بسیار کمی از الگوریتم های موازی به سرعت بهینه دست می یابند. اکثر آنها برای تعداد کمی از عناصر پردازشی دارای یک سرعت تقریباً خطی هستند که برای تعداد زیادی از عناصر پردازشی به یک مقدار ثابت تبدیل می شود.
← مرکز محاسبات سریع شبیهسازان امیرکبیر →
سرعت بالقوه یک الگوریتم در یک پلت فرم محاسباتی موازی توسط قانون Amdahl ارائه شده است[15]
جایی که
تأخیر سرعت بالقوه در تأخیر اجرای کل کار است.
s سرعت تأخیر اجرای بخش قابل موازی سازی وظیفه است.
p درصدی از زمان اجرای کل کار مربوط به قسمت موازی پذیر کار قبل از موازی سازی است.
از آنجایی که Slatency < 1/(1 – p)، نشان می دهد که بخش کوچکی از برنامه که نمی تواند موازی شود، سرعت کلی موجود از موازی سازی را محدود می کند. برنامه ای که یک مسئله بزرگ ریاضی یا مهندسی را حل می کند معمولاً از چندین بخش موازی پذیر و چندین بخش غیرقابل موازی سازی (سریالی) تشکیل می شود. اگر بخش غیرقابل موازی سازی یک برنامه 10 درصد از زمان اجرا را به خود اختصاص دهد (9/0=p)، بدون در نظر گرفتن تعداد پردازنده اضافه شده، نمی توانیم بیش از 10 برابر افزایش سرعت داشته باشیم. این یک حد بالایی برای سودمندی افزودن واحدهای اجرایی موازی بیشتر قرار می دهد. «وقتی به دلیل محدودیتهای متوالی نمیتوان یک کار را تقسیم کرد، اعمال تلاش بیشتر تأثیری در برنامه ندارد. بچهدار شدن نه ماه طول میکشد، مهم نیست که چند زن تعیین شوند».[16]
یک نمایش گرافیکی از قانون گوستافسون
قانون Amdahl فقط در مواردی اعمال می شود که اندازه مشکل ثابت شده باشد. در عمل، با در دسترس قرار گرفتن منابع محاسباتی بیشتر، آنها تمایل دارند در مسائل بزرگتر (مجموعه داده های بزرگتر) استفاده شوند و زمان صرف شده در بخش قابل موازی سازی اغلب بسیار سریعتر از کار ذاتی سریال رشد می کند.[17] در این مورد، قانون گوستافسون ارزیابی کمتر بدبینانه و واقع بینانه تری از عملکرد موازی ارائه می دهد:[18]
هم قانون Amdahl و هم قانون Gustafson فرض می کنند که زمان اجرای قسمت سریال برنامه مستقل از تعداد پردازنده ها است. قانون آمدال فرض می کند که کل مشکل اندازه ثابتی دارد به طوری که کل مقدار کاری که باید به صورت موازی انجام شود نیز مستقل از تعداد پردازنده ها است، در حالی که قانون گوستافسون فرض می کند که مقدار کل کاری که باید به صورت موازی انجام شود به صورت خطی با تعداد پردازنده ها
وابستگی ها
درک وابستگی داده ها در پیاده سازی الگوریتم های موازی اساسی است. هیچ برنامه ای نمی تواند سریعتر از طولانی ترین زنجیره محاسبات وابسته (معروف به مسیر بحرانی) اجرا شود، زیرا محاسباتی که به محاسبات قبلی در زنجیره بستگی دارند باید به ترتیب اجرا شوند. با این حال، اکثر الگوریتم ها فقط از یک زنجیره طولانی از محاسبات وابسته تشکیل نمی شوند. معمولا فرصت هایی برای اجرای محاسبات مستقل به صورت موازی وجود دارد.
اجازه دهید Pi و Pj دو بخش برنامه باشند. شرایط برنشتاین[19] زمانی را توصیف میکند که این دو مستقل هستند و میتوانند به صورت موازی اجرا شوند. برای Pi، بگذارید Ii همه متغیرهای ورودی و Oi متغیرهای خروجی باشد و به همین ترتیب برای Pj. Pi و Pj در صورت رضایت، مستقل هستند
نقض شرط اول یک وابستگی به جریان را ایجاد می کند که مربوط به بخش اول است که نتیجه ای را ایجاد می کند که توسط بخش دوم استفاده می شود. شرط دوم نشان دهنده یک ضد وابستگی است، زمانی که بخش دوم یک متغیر مورد نیاز بخش اول را تولید می کند. شرط سوم و نهایی نشان دهنده یک وابستگی خروجی است: وقتی دو بخش در یک مکان می نویسند، نتیجه از آخرین بخش اجرا شده منطقاً می آید.[20]
شرایط مسابقه، طرد متقابل، همگام سازی و کاهش سرعت موازی
وظایف فرعی در یک برنامه موازی اغلب رشته نامیده می شود. برخی از معماریهای موازی کامپیوتر از نسخههای کوچکتر و سبکتر رشتهها به نام فیبر استفاده میکنند، در حالی که برخی دیگر از نسخههای بزرگتر به نام فرآیندها استفاده میکنند. با این حال، “رشته ها” به طور کلی به عنوان یک اصطلاح عمومی برای وظایف فرعی پذیرفته شده است.[21] موضوعات اغلب نیاز به دسترسی همگام به یک شی یا منابع دیگر دارند، برای مثال زمانی که باید متغیری را که بین آنها به اشتراک گذاشته شده است به روز کنند. بدون همگام سازی، دستورالعمل های بین دو رشته ممکن است به هر ترتیبی در هم آمیخته شوند.
اگر دستور 1B بین 1A و 3A اجرا شود، یا اگر دستور 1A بین 1B و 3B اجرا شود، برنامه داده های نادرستی تولید می کند. این به عنوان شرایط مسابقه شناخته می شود. برنامه نویس باید از یک قفل برای ارائه انحراف متقابل استفاده کند. قفل یک ساختار زبان برنامه نویسی است که به یک رشته اجازه می دهد تا کنترل یک متغیر را در دست بگیرد و از خواندن یا نوشتن آن توسط رشته های دیگر جلوگیری کند، تا زمانی که آن متغیر باز شود. رشته ای که قفل را نگه می دارد برای اجرای بخش حیاتی خود (بخشی از یک برنامه که نیاز به دسترسی انحصاری به برخی متغیرها دارد) و باز کردن قفل داده ها پس از اتمام آزاد است.
یک رشته با موفقیت متغیر V را قفل می کند، در حالی که رشته دیگر قفل می شود – تا زمانی که قفل V دوباره باز نشود ادامه پیدا نمی کند. این امر اجرای صحیح برنامه را تضمین می کند. قفل ها ممکن است برای اطمینان از اجرای صحیح برنامه زمانی که رشته ها باید دسترسی به منابع را سریالی کنند، ضروری باشد، اما استفاده از آنها می تواند تا حد زیادی یک برنامه را کند کند و ممکن است بر قابلیت اطمینان آن تأثیر بگذارد.[22]
قفل کردن چندین متغیر با استفاده از قفل های غیر اتمی امکان بن بست برنامه را معرفی می کند. یک قفل اتمی چندین متغیر را به طور همزمان قفل می کند. اگر نتواند همه آنها را قفل کند، هیچ کدام را قفل نمی کند. اگر دو thread هر کدام نیاز به قفل کردن همان دو متغیر با استفاده از قفل های غیر اتمی داشته باشند، ممکن است یک رشته یکی از آنها را قفل کند و رشته دوم متغیر دوم را قفل کند. در چنین حالتی، هیچ یک از رشته ها نمی توانند کامل شوند و بن بست نتیجه می گیرد.[23]
بسیاری از برنامه های موازی نیاز دارند که وظایف فرعی آنها همزمان عمل کنند. این مستلزم استفاده از یک مانع است. موانع معمولاً با استفاده از قفل یا سمافور اجرا میشوند.[24] یک دسته از الگوریتم ها که به نام الگوریتم های بدون قفل و بدون انتظار شناخته می شوند، به طور کلی از استفاده از قفل ها و موانع جلوگیری می کنند. با این حال، اجرای این رویکرد به طور کلی دشوار است و به ساختارهای داده ای به درستی طراحی شده نیاز دارد.[25]
همه موازی سازی ها منجر به افزایش سرعت نمی شود. به طور کلی، از آنجایی که یک کار به رشتههای بیشتر و بیشتری تقسیم میشود، آن رشتهها بخش فزایندهای از زمان خود را صرف برقراری ارتباط با یکدیگر یا انتظار یکدیگر برای دسترسی به منابع میکنند.[26][27] هنگامی که سربار ناشی از اختلاف منابع یا ارتباطات بر زمان صرف شده برای محاسبات دیگر غالب شود، موازی سازی بیشتر (یعنی تقسیم حجم کار بر روی رشته های بیشتر) به جای کاهش مدت زمان مورد نیاز برای اتمام، افزایش می یابد. این مشکل که به عنوان کاهش سرعت موازی شناخته می شود، [28] می تواند در برخی موارد با تجزیه و تحلیل نرم افزار و طراحی مجدد بهبود یابد.[29]
موازی سازی ریزدانه، درشت دانه و شرم آور
برنامهها اغلب بر اساس تعداد دفعاتی که وظایف فرعی آنها نیاز به همگامسازی یا برقراری ارتباط با یکدیگر دارند، طبقهبندی میشوند. اگر یک برنامه کاربردی موازی ریز دانه را نشان می دهد اگر وظایف فرعی آن باید چندین بار در ثانیه ارتباط برقرار کنند. اگر آنها بارها در ثانیه ارتباط برقرار نکنند، توازی درشت دانه از خود نشان می دهد، و اگر به ندرت یا هرگز مجبور به برقراری ارتباط نباشند، موازی کاری شرم آور نشان می دهد. برنامه های موازی شرم آور ساده ترین برای موازی سازی در نظر گرفته می شوند.
طبقه بندی فلین
مایکل جی فلین یکی از اولین سیستمهای طبقهبندی را برای کامپیوترها و برنامههای موازی (و ترتیبی) ایجاد کرد که اکنون به عنوان طبقهبندی فلین شناخته میشود. فلین برنامهها و رایانهها را بر اساس اینکه آیا آنها با استفاده از یک مجموعه واحد یا چندین مجموعه از دستورالعملها کار میکنند و اینکه آیا این دستورالعملها از یک مجموعه واحد یا چندین مجموعه داده استفاده میکنند یا نه، طبقهبندی کرد.
طبقه بندی فلین
جریان داده واحد
SISDMISD
جریان های داده های متعدد
SIMDMIMD
زیرمجموعه های SIMD[30]
پردازش آرایه (SIMT) پردازش خطی (SIMD بسته بندی شده) پردازش انجمنی (SIMD پیش فرض/ماسک شده)
همچنین ببینید
SPMDMPMD
طبقه بندی تک دستورالعمل-تک داده (SISD) معادل یک برنامه کاملاً متوالی است. طبقه بندی تک دستور العمل-چند داده (SIMD) مشابه انجام عملیات مشابه به طور مکرر بر روی یک مجموعه داده بزرگ است. این معمولا در برنامه های پردازش سیگنال انجام می شود. چند دستور العمل تک داده (MISD) یک طبقه بندی به ندرت استفاده می شود. در حالی که معماریهای کامپیوتری برای مقابله با این ابداع شد (مانند آرایههای سیستولیک)، تعداد کمی از برنامههای کاربردی که متناسب با این کلاس بودند، تحقق یافت. برنامه های چند دستور العمل چندگانه (MIMD) تا حد زیادی رایج ترین نوع برنامه های موازی هستند.
به گفته دیوید ا. شاید به دلیل قابل درک بودن آن – پرکاربردترین طرح.»[31]
← اجاره ابر رایانه →


