پردازش موازی و پایگاه های داده موازی
این فصل پردازش موازی و فناوریهای پایگاه داده موازی را معرفی میکند که مزایای بزرگی را برای پردازش تراکنشهای آنلاین و برنامههای کاربردی پشتیبانی تصمیم ارائه میدهد. چالش مدیر این است که به طور انتخابی این فناوری را برای استفاده کامل از قدرت چند پردازشی آن به کار گیرد.
برای انجام موفقیت آمیز این کار، باید بدانید که چند پردازش چگونه کار می کند، به چه منابعی نیاز دارد، و چه زمانی می توانید یا نمی توانید آن را به طور موثر اعمال کنید. این فصل به سوالات زیر پاسخ می دهد:
پردازش موازی تعریف شده است
پردازش موازی یک کار بزرگ را به بسیاری از وظایف کوچکتر تقسیم می کند و وظایف کوچکتر را همزمان بر روی چندین گره اجرا می کند. در نتیجه، کار بزرگتر سریعتر تکمیل می شود.
توجه: یک گره یک پردازنده مجزا است که اغلب روی یک ماشین جداگانه قرار دارد. با این حال، چندین پردازنده می توانند روی یک ماشین قرار گیرند.
برخی از وظایف را می توان به طور موثر تقسیم کرد، و بنابراین کاندیدهای خوبی برای پردازش موازی هستند. با این حال، سایر وظایف خود را به این رویکرد وام نمی دهد.
به عنوان مثال، در بانکی که تنها یک عابر بانک دارد، همه مشتریان باید یک صف واحد تشکیل دهند تا به آنها خدمات ارائه شود. با دو گوینده، کار می تواند به طور موثر تقسیم شود به طوری که مشتریان دو صف تشکیل دهند و دو برابر سریعتر به آنها خدمات داده شود یا می توانند یک صف واحد برای ایجاد عدالت تشکیل دهند. این نمونه ای است که در آن پردازش موازی یک راه حل موثر است.
در مقابل، اگر مدیر بانک باید تمام درخواستهای وام را تأیید کند، پردازش موازی لزوماً جریان وامها را تسریع نمیکند. مهم نیست که چند عابر برای رسیدگی به وام ها وجود دارد، همه درخواست ها باید یک صف واحد برای تایید مدیر بانک تشکیل دهند. هیچ مقدار پردازش موازی نمی تواند بر این گلوگاه داخلی سیستم غلبه کند.
شکل 1-1 و شکل 1-2 پردازش متوالی یک پرس و جو موازی منفرد با پردازش موازی همان پرس و جو را تضاد دارند.
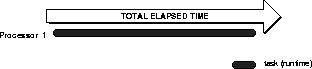
شکل 1-2 پردازش موازی: اجرای وظایف جزء به صورت موازی

در پردازش متوالی، پرس و جو به عنوان یک کار بزرگ اجرا می شود. در پردازش موازی، پرس و جو به چندین کار کوچکتر تقسیم می شود و هر وظیفه جزء بر روی یک گره جداگانه اجرا می شود.
شکل 1-3 و شکل 1-4 پردازش متوالی را با پردازش موازی چندین کار مستقل از یک محیط پردازش تراکنش آنلاین (OLTP) مقایسه می کنند.
شکل 1-3 پردازش متوالی وظایف مستقل چندگانه

در پردازش متوالی، وظایف مستقل برای یک منبع با هم رقابت می کنند. فقط وظیفه 1 بدون نیاز به انتظار اجرا می شود. وظیفه 2 باید منتظر بماند تا کار 1 تکمیل شود. وظیفه 3 باید منتظر بماند تا وظایف 1 و 2 تکمیل شود و غیره. (اگرچه شکل وظایف مستقل را به اندازه یکسان نشان می دهد، اما اندازه وظایف متفاوت خواهد بود.) در مقابل، در پردازش موازی (به عنوان مثال، یک سرور موازی در یک چند پردازنده متقارن)، قدرت CPU بیشتری به وظایف اختصاص داده می شود. هر کار مستقل بلافاصله روی پردازنده خودش اجرا می شود: هیچ زمان انتظاری در کار نیست.
مشکلات پردازش موازی
اجرای موثر پردازش موازی شامل دو چالش است:
ساختار دهی به وظایف به گونه ای که برخی وظایف می توانند همزمان (به صورت موازی) اجرا شوند.
حفظ توالی کارهایی که باید به صورت سریالی اجرا شوند
ویژگی های یک سیستم موازی
یک سیستم پردازش موازی دارای ویژگی های زیر است:
هر پردازنده در یک سیستم می تواند وظایف را همزمان انجام دهد.
کارها ممکن است نیاز به همگام سازی داشته باشند.
گره ها معمولا منابعی مانند داده ها، دیسک ها و سایر دستگاه ها را به اشتراک می گذارند.
پردازش موازی برای SMP و MPP
معماری های پردازش موازی ممکن است از:
سخت افزار خوشه ای و پردازش موازی انبوه (MPP) که در آن هر گره حافظه خاص خود را دارد.
سیستمهای تک حافظه – همچنین به عنوان سختافزار متقارن چند پردازشی (SMP) شناخته میشوند که در آن چندین پردازنده از یک منبع حافظه استفاده میکنند.
ماشین های Clustered و MPP دارای حافظه های متعددی هستند که هر CPU معمولاً حافظه مخصوص به خود را دارد. چنین سیستم هایی با استفاده از حافظه کالا و اجزای اتوبوس برای از بین بردن تنگناهای حافظه، مزایای قابل توجه قیمت/عملکرد را نوید می دهند.
سیستم های مدیریت پایگاه داده که تنها از یک نوع سخت افزار پشتیبانی می کنند، قابلیت حمل برنامه ها، پتانسیل انتقال برنامه ها به سیستم های سخت افزاری جدید و مقیاس پذیری برنامه ها را محدود می کنند. سرور موازی اوراکل (OPS) هم از کلاسترها و هم از سیستم های MPP بهره برداری می کند و چنین محدودیتی ندارد. Oracle بدون گزینه سرور موازی از ماشینهای واحد CPU یا SMP بهرهبرداری میکند.
پردازش موازی برای عملیات یکپارچه
نرم افزار پایگاه داده موازی باید به طور موثر قدرت پردازش سیستم را برای رسیدگی به برنامه های کاربردی مختلف به کار گیرد: برنامه های کاربردی پردازش تراکنش آنلاین (OLTP)، برنامه های کاربردی سیستم پشتیبانی تصمیم (DSS)، و همچنین حجم کاری ترکیبی OLTP و DSS. برنامه های OLTP با تراکنش های کوتاه مشخص می شوند که از CPU و I/O کم استفاده می کنند. برنامه های DSS با تراکنش های طولانی، با استفاده از CPU و I/O بالا مشخص می شوند.
نرم افزار پایگاه داده موازی اغلب تخصصی است – معمولاً به عنوان پردازشگر پرس و جو عمل می کند. با این حال، از آنجایی که آنها برای ارائه یک عملکرد واحد طراحی شده اند، سرورهای تخصصی یک پایه مشترک برای عملیات یکپارچه ارائه نمی دهند. اینها شامل پشتیبانی تصمیم گیری آنلاین، گزارش دسته ای، انبار داده، OLTP، عملیات توزیع شده و سیستم های در دسترس بودن بالا است. سرورهای تخصصی بیشترین موفقیت را در زمینه پایگاه های داده بسیار بزرگ داشته اند: برای مثال در برنامه های DSS.
نرم افزار پایگاه داده موازی همه کاره باید قیمت/عملکرد عالی را بر روی سخت افزار سیستم های باز ارائه دهد و به گونه ای طراحی شود که طیف گسترده ای از نیازهای محاسباتی سازمانی را برآورده کند. ویژگیهایی مانند پشتیبانگیری آنلاین، تکثیر دادهها، قابلیت حمل، قابلیت همکاری و پشتیبانی از طیف گستردهای از ابزارهای کلاینت میتواند سرور موازی را برای پشتیبانی از یکپارچهسازی برنامهها، عملیات توزیعشده و بارهای کاری ترکیبی برنامه فعال کند.
پایگاه داده موازی چیست؟
انواع معماریهای سختافزاری به چندین رایانه اجازه میدهند تا دسترسی به دادهها، نرمافزار یا دستگاههای جانبی را به اشتراک بگذارند. یک پایگاه داده موازی برای استفاده از چنین معماری هایی با اجرای چندین نمونه طراحی شده است که یک پایگاه داده فیزیکی واحد را به اشتراک می گذارند. در برنامههای کاربردی مناسب، یک سرور موازی میتواند با افزایش کارایی، امکان دسترسی به یک پایگاه داده را برای کاربران در چندین ماشین فراهم کند.
یک سرور موازی تراکنش ها را به صورت موازی با سرویس دادن به جریانی از تراکنش ها با استفاده از چندین CPU در گره های مختلف پردازش می کند، جایی که هر CPU یک تراکنش کامل را پردازش می کند. با استفاده از زبان دستکاری داده های موازی می توانید یک تراکنش را توسط چندین گره انجام دهید. این یک رویکرد کارآمد است زیرا بسیاری از برنامهها از تراکنشهای درج و بهروزرسانی آنلاین تشکیل شدهاند که نیاز به دسترسی کوتاه به داده دارند. پایگاه داده موازی علاوه بر متعادل کردن حجم کار در میان CPU ها، دسترسی همزمان به داده ها را فراهم می کند و از یکپارچگی داده ها محافظت می کند.
عناصر کلیدی پردازش موازی چیست؟
این بخش عناصر کلیدی پردازش موازی را شرح می دهد:
افزایش سرعت و مقیاس: اهداف پردازش موازی
همگام سازی: یک عامل حیاتی موفقیت
قفل کردن
پیام رسانی
افزایش سرعت و مقیاس: اهداف پردازش موازی
شما می توانید اهداف عملکرد پردازش موازی را بر اساس دو ویژگی مهم اندازه گیری کنید:
سرعت دادن
افزایش مقیاس
سرعت دادن
Speedup به میزانی گفته می شود که سخت افزار بیشتری می تواند یک کار را در زمان کمتری نسبت به سیستم اصلی انجام دهد. با سخت افزار اضافه شده، سرعت بالا کار را ثابت نگه می دارد و صرفه جویی در زمان را اندازه گیری می کند. شکل 1-5 نشان می دهد که چگونه هر سیستم سخت افزاری موازی نیمی از وظیفه اصلی را در نیمی از زمان لازم برای انجام آن در یک سیستم واحد انجام می دهد.
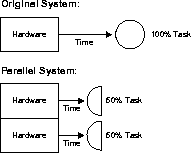
شکل 1-5 افزایش سرعت
با سرعت خوب، پردازنده های اضافی زمان پاسخگویی سیستم را کاهش می دهند. شما می توانید سرعت را با استفاده از این فرمول اندازه گیری کنید:
جایی که
زمان_موازی
زمان سپری شده توسط یک سیستم موازی بزرگتر برای کار داده شده است
به عنوان مثال، اگر سیستم اصلی برای انجام یک کار 60 ثانیه طول بکشد، و دو سیستم موازی 30 ثانیه طول بکشد، آنگاه مقدار افزایش سرعت برابر با 2 خواهد بود.
مقدار n، جایی که n برابر سخت افزار بیشتر استفاده می شود، ایده آل سرعت خطی را نشان می دهد: زمانی که دو برابر سخت افزار می تواند یک کار را در نیمی از زمان انجام دهد (یا زمانی که سه برابر سخت افزار همان کار را در یک سوم انجام می دهد. زمان و غیره).
توجه: برای اکثر برنامه های OLTP، نمی توان انتظار افزایش سرعت داشت: فقط افزایش مقیاس. سربار ناشی از همگام سازی ممکن است در واقع باعث کاهش سرعت شود.
افزایش مقیاس
Scaleup عامل m است که بیان می کند که در یک بازه زمانی یکسان چقدر کار بیشتری می توان توسط یک سیستم n برابر بزرگتر انجام داد. با سخت افزار اضافه شده، فرمولی برای افزایش مقیاس، زمان را ثابت نگه می دارد و اندازه افزایش یافته کاری را که می توان انجام داد اندازه گیری می کند.
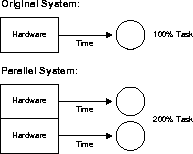
شکل 1-6 مقیاس بندی
همگام سازی: یک عامل حیاتی موفقیت
هماهنگی وظایف همزمان را همگام سازی می گویند. همگام سازی برای درستی لازم است. کلید پردازش موازی موفقیت آمیز این است که وظایف را به گونه ای تقسیم کنید که همگام سازی بسیار کمی لازم باشد. هرچه همگام سازی کمتری لازم باشد، سرعت و افزایش مقیاس بهتر است.
در پردازش موازی بین گره ها، یک اتصال پرسرعت بین پردازنده های موازی مورد نیاز است. سربار این همگام سازی می تواند بسیار گران باشد اگر ارتباطات بین گره ای زیادی لازم باشد. برای پردازش موازی در یک گره، پیام رسانی ضروری نیست: به جای آن از حافظه مشترک استفاده می شود. پیام رسانی و قفل کردن بین گره ها توسط مدیر قفل توزیع شده یکپارچه (IDLM) انجام می شود.
میزان همگام سازی به میزان منابع و تعداد کاربران و وظایفی که روی منابع کار می کنند بستگی دارد. ممکن است برای هماهنگ کردن تعداد کمی از کارهای همزمان به همگام سازی کمی نیاز باشد، اما برای هماهنگ کردن بسیاری از کارهای همزمان ممکن است همگام سازی زیادی لازم باشد.
در بالای سر
مقدار زیادی از زمان صرف شده در همگام سازی نشان دهنده رقابت زیاد برای منابع است.
توجه: زمان زیادی که صرف همگام سازی می شود می تواند مزایای پردازش موازی را کاهش دهد. با صرف زمان کمتر در هماهنگ سازی، می توان به سرعت و افزایش مقیاس بهتری دست یافت.
هزینه همگام سازی
در حالی که همگام سازی یک عنصر ضروری از پردازش موازی برای حفظ صحت است، شما باید هزینه آن را از نظر عملکرد و منابع سیستم مدیریت کنید. انواع مختلف نرم افزارهای پردازش موازی ممکن است امکان دستیابی به همگام سازی را فراهم کنند، اما یک رویکرد معین ممکن است مقرون به صرفه باشد یا نباشد.
گاهی اوقات همگام سازی را می توان بسیار ارزان انجام داد. با این حال، در موارد دیگر، هزینه همگام سازی ممکن است بسیار زیاد باشد. به عنوان مثال، اگر یک جدول از بسیاری از گره ها درج می کند، همگام سازی زیادی لازم است. اختلاف زیادی از سوی گرههای مختلف برای درج در یک بلوک داده وجود دارد: بلوک داده باید بین گرههای مختلف منتقل شود. این نوع همگام سازی را می توان انجام داد – اما نه به طور موثر.
همچنین نگاه کنید به: فصل 12، “تحلیل برنامه”
فصل 19، “تنظیم سیستم برای بهینه سازی عملکرد”
فصل 8، “مدیر قفل توزیع شده یکپارچه: دسترسی به منابع”
قفل کردن
قفل ها اساساً راهی برای همگام سازی وظایف هستند. مکانیسم های مختلف قفل کردن برای فعال کردن همگام سازی وظایف مورد نیاز توسط پردازش موازی ضروری است.
مدیریت قفل توزیع شده یکپارچه (یکپارچه DLM یا IDLM) تسهیلات قفل داخلی است که با سرور موازی Oracle استفاده می شود. به اشتراک گذاری منابع بین گره هایی که یک سرور موازی را اجرا می کنند، هماهنگ می کند. نمونه های یک سرور موازی از مدیر قفل توزیع شده یکپارچه برای برقراری ارتباط با یکدیگر و هماهنگی اصلاح منابع پایگاه داده استفاده می کنند. هر گره مستقل از گره های دیگر عمل می کند، مگر زمانی که برای منبع مشابهی تلاش می کند.
توجه: در Oracle8، امکانات مدیریت قفل توزیعشده یکپارچه جایگزین مدیریت قفل توزیعشده خارجی (DLM) میشود که در نسخههای قبلی استفاده میشد. این بهبود عملکرد Oracle را از محدودیت های مدیران قفل خارجی رها می کند.
IDLM به برنامهها اجازه میدهد تا دسترسی به منابعی مانند دادهها، نرمافزار و دستگاههای جانبی را همگامسازی کنند، به طوری که درخواستهای همزمان برای همان منبع بین برنامههای در حال اجرا بر روی گرههای مختلف هماهنگ شود.
IDLM خدمات زیر را برای برنامه های کاربردی انجام می دهد:
“مالکیت” فعلی یک منبع را پیگیری می کند
درخواست های قفل برای منابع از فرآیندهای برنامه را می پذیرد
هنگامی که یک قفل در یک منبع در دسترس است، روند درخواست را مطلع می کند
به یک منبع برای یک فرآیند دسترسی پیدا می کند
پیام رسانی
پردازش موازی نیاز به ارتباط سریع و کارآمد بین گره ها دارد: سیستمی با پهنای باند بالا و تاخیر کم که به طور موثر با IDLM ارتباط برقرار می کند.
پهنای باند اندازه کل پیام هایی است که می توان در هر ثانیه ارسال کرد. تأخیر زمانی است (بر حسب ثانیه) که طول می کشد تا یک پیام در اتصال داخلی قرار گیرد. بنابراین تأخیر تعداد پیامهایی را نشان میدهد که میتوان در هر ثانیه روی اتصال داخلی قرار داد. یک اتصال متقابل با پهنای باند بالا مانند یک بزرگراه عریض با خطوط زیاد برای جابجایی ترافیک سنگین است: تعداد خطوط بر سرعت حرکت ترافیک تأثیر میگذارد. یک اتصال متقابل با تأخیر کم مانند یک بزرگراه با یک رمپ ورودی است که به وسایل نقلیه اجازه می دهد بدون تأخیر وارد شوند: هزینه سوار شدن در بزرگراه کم است.
اکثر سیستمها و خوشههای MPP با شبکههایی طراحی میشوند که پهنای باند نسبتاً بالایی دارند. از سوی دیگر، تأخیر یک مشکل سیستم عامل است که عمدتاً به نرم افزار مربوط می شود. سیستم های MPP و اکثر خوشه ها به طور مشخص از اتصالات با پهنای باند بالا و تأخیر کم استفاده می کنند. خوشه های دیگر ممکن است از اتصالات اترنت با پهنای باند نسبتا کم و تأخیر بالا استفاده کنند.
توان عملیاتی پیشرفته: افزایش مقیاس
اگر وظایف بتوانند مستقل از یکدیگر اجرا شوند، میتوانند در CPUها یا گرههای مختلف توزیع شوند و یک مقیاسبندی وجود خواهد داشت: فرآیندهای بیشتری میتوانند در مدت زمان یکسان در پایگاه داده اجرا شوند.
اگر فرآیندها ده برابر سریعتر اجرا شوند، سیستم میتواند ده برابر بیشتر در مدت زمان اولیه انجام دهد. به عنوان مثال، ویژگی پرس و جوی موازی، امکان افزایش مقیاس را فراهم می کند: اگر داده های درخواست شده ده برابر افزایش یابد، یا اگر بتوان به کاربران بیشتری خدمات رسانی کرد، ممکن است یک سیستم زمان پاسخ یکسانی را حفظ کند. سرور موازی اوراکل بدون ویژگی پرس و جوی موازی نیز امکان افزایش مقیاس را فراهم می کند، اما با اجرای یک پرس و جو به صورت متوالی بر روی گره های مختلف.
با حجم کاری ترکیبی از DSS، OLTP و برنامههای گزارشدهی، میتوان با اجرای برنامههای متعدد بر روی گرههای مختلف، به افزایش مقیاس رسید. همچنین اگر برنامههای دستهای را بازنویسی کنید و آنها را به تعدادی جریان موازی تقسیم کنید تا از چندین CPU که اکنون در دسترس هستند استفاده کنید، میتوانید به سرعت بالا دست پیدا کنید.
بهبود زمان پاسخ: افزایش سرعت
برنامه های کاربردی DSS و پرس و جوی موازی می توانند با پردازش موازی سرعت بیشتری کسب کنند: هر تراکنش می تواند سریعتر اجرا شود.
با این حال، برای برنامه های OLTP، نمی توان انتظار افزایش سرعت داشت: فقط افزایش مقیاس. در برنامههای OLTP، هر فرآیند مستقل است: حتی با پردازش موازی، هر درج یا بهروزرسانی در جدول سفارش همچنان با همان سرعت اجرا میشود. در واقع، سربار ناشی از همگام سازی ممکن است باعث کاهش جزئی سرعت شود. از آنجایی که هر یک از عملیات انجام شده کوچک است، تلاش برای موازی کردن آنها نامناسب است. سربار بیشتر از سود خواهد بود.
سرعت را می توان با پردازش دسته ای نیز به دست آورد، اما درجه افزایش سرعت به همگام سازی بین وظایف بستگی دارد.
مزایای پایگاه داده موازی چیست؟
فناوری پایگاه داده موازی می تواند با فعال کردن موارد زیر به انواع خاصی از برنامه ها کمک کند:
عملکرد بالاتر
در دسترس بودن بالاتر
انعطاف پذیری بیشتر
کاربران بیشتر
عملکرد بالاتر
با CPU های بیشتر در دسترس برای یک برنامه، می توان به سرعت و مقیاس بالاتری دست یافت. بهبود عملکرد به میزان فعالیتهای قفل کردن و همگامسازی بین گره بستگی دارد. هر عملیات قفل پردازشگر و پیام فشرده است. می تواند تاخیر زیادی داشته باشد. حجم عملیات قفل و اختلاف پایگاه داده و همچنین توان عملیاتی و عملکرد IDLM، در نهایت مقیاس پذیری سیستم را تعیین می کند.
در دسترس بودن بالاتر
گره ها از یکدیگر جدا می شوند، بنابراین شکست در یک گره کل سیستم را از بین نمی برد. گره های باقی مانده می توانند گره شکست خورده را بازیابی کنند و به ارائه دسترسی به داده ها برای کاربران ادامه دهند. این بدان معنی است که داده ها بسیار بیشتر از یک گره در هنگام خرابی گره در دسترس هستند و به میزان قابل توجهی در دسترس بودن پایگاه داده بالاتر است.
انعطاف پذیری بیشتر
یک محیط Oracle Parallel Server بسیار انعطاف پذیر است. در صورت لزوم می توان نمونه ها را تخصیص داد یا تخصیص داد. هنگامی که تقاضای زیادی برای پایگاه داده وجود دارد، نمونه های بیشتری را می توان به طور موقت اختصاص داد. زمانی که دیگر ضروری نباشند، میتوان نمونهها را اختصاص داد و برای مقاصد دیگر استفاده کرد.
کاربران بیشتر
فناوری پایگاه داده موازی می تواند غلبه بر محدودیت های حافظه را ممکن کند و یک سیستم واحد را قادر می سازد تا به هزاران کاربر خدمات رسانی کند.
← مرکز محاسبات سریع شبیهسازان امیرکبیر →
آیا سرور موازی پیکربندی Oracle مورد نیاز شماست؟
این بخش پیکربندی های Oracle زیر را توضیح می دهد که می تواند عملکرد بالایی را برای انواع مختلف برنامه ها ارائه دهد:
تک نمونه با دسترسی انحصاری
سیستم پایگاه داده چند نمونه ای
سیستم پایگاه داده توزیع شده
سیستم های کلاینت-سرور
سرور موازی یکی از چندین گزینه Oracle است که یک پایگاه داده رابطهای با کارایی بالا برای بسیاری از کاربران ارائه میکند. این تنظیمات را می توان با توجه به نیازهای شما ترکیب کرد. یک سرور موازی می تواند یکی از چندین سرور در یک محیط پایگاه داده توزیع شده باشد، و پیکربندی سرویس گیرنده-سرور می تواند پیکربندی های مختلف اوراکل را در یک سیستم ترکیبی برای برآوردن نیازهای برنامه خاص ترکیب کند.
توجه: پشتیبانی از هر پیکربندی Oracle به پلتفرم وابسته است. بررسی کنید تا تأیید کنید که پلتفرم شما از پیکربندی مورد نظر شما پشتیبانی می کند.
برای عملکرد بهینه، سیستم خود را بر اساس نیازهای برنامه خاص و منابع موجود پیکربندی کنید، سپس پایگاه داده و برنامه های کاربردی را طراحی و تنظیم کنید تا بهترین استفاده را از پیکربندی داشته باشید. همچنین مهاجرت سخت افزار یا نرم افزار موجود به سیستم جدید یا سیستم های آینده را در نظر بگیرید.
بخش های زیر به شما کمک می کند تا تعیین کنید کدام پیکربندی Oracle به بهترین وجه نیازهای شما را برآورده می کند.
همچنین نگاه کنید به: فصل 3، “معماری سخت افزار موازی”
تک نمونه با دسترسی انحصاری
شکل 1-7 یک سیستم پایگاه داده تک نمونه ای را نشان می دهد که بر روی یک چند پردازنده متقارن (SMP) اجرا می شود. پایگاه داده خود روی مجموعه ای از دیسک ها قرار دارد.

شکل 1-7 سیستم پایگاه داده تک نمونه
دسترسی یک نمونه به یک پایگاه داده واحد می تواند با اجرای بر روی یک کامپیوتر بزرگتر عملکرد را بهبود بخشد. یک کامپیوتر منفرد بزرگ نیازی به هماهنگی بین چندین گره ندارد و عموما بهتر از دو کامپیوتر کوچک در یک سیستم چند گره ای عمل می کند. با این حال، دو کامپیوتر کوچک اغلب کمتر از یک کامپیوتر بزرگ قیمت دارند.
اگر بخواهید از یک کامپیوتر به یک سیستم چند گره مهاجرت کنید، هزینه طراحی مجدد و تنظیم پایگاه داده و برنامه های کاربردی برای گزینه سرور موازی ممکن است قابل توجه باشد. در شرایطی مانند این، در نظر بگیرید که آیا یک کامپیوتر بزرگتر ممکن است راه حل بهتری نسبت به انتقال به یک سرور موازی باشد یا خیر.
همچنین برای اطلاعات کامل درباره Oracle تک نمونه به: Oracle8 Concepts مراجعه کنید.
سیستم پایگاه داده چند نمونه ای
Oracle با گزینه سرور موازی در حال اجرا بر روی یک خوشه یا MPP یک سیستم پایگاه داده چند نمونه ای نامیده می شود که در شکل 1-8 نشان داده شده است. این یک راه حل عالی برای برنامه هایی است که می توانند پیکربندی شوند تا انتقال داده ها بین نمونه ها در گره های مختلف را به حداقل برسانند.
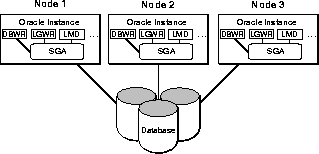
شکل 1-8 سیستم پایگاه داده چند نمونه ای
توجه داشته باشید که این سیستم پایگاه داده به فرآیند LMD در هر نمونه نیاز دارد. این فرآیندها برای هماهنگ کردن قفل جهانی با یکدیگر ارتباط برقرار می کنند.
در سرور موازی، نمونه ها از پایگاه داده جدا می شوند. در حالت انحصاری، یک مکاتبه یک به یک نمونه با پایگاه داده وجود دارد. با این حال، در حالت اشتراکی (موازی)، نمونه های زیادی برای یک پایگاه داده واحد وجود دارد.
به طور کلی، هر برنامه کاربردی زمانی بهترین عملکرد را دارد که به یک پایگاه داده در یک سیستم بزرگتر دسترسی انحصاری داشته باشد، در مقایسه با عملکرد آن در یک گره کوچکتر از یک محیط چند گره. این به این دلیل است که اگر به یک محیط چند گره بروید، هزینه همگامسازی ممکن است بسیار زیاد شود. تفاوت عملکرد به ویژگی های آن برنامه و سایر برنامه هایی که دسترسی به پایگاه داده را به اشتراک می گذارند بستگی دارد.
برنامه های کاربردی با یک یا هر دو ویژگی زیر برای اجرا بر روی نمونه های جداگانه سرور موازی مناسب هستند:
برنامه هایی که در درجه اول داده ها را پرس و جو می کنند
برنامههایی که گروههای جدا از بلوکهای داده را تغییر میدهند یا همان بلوکهای داده را در زمانهای مختلف تغییر میدهند
همچنین ببینید: “فعال کردن و غیرفعال کردن سرور موازی” در صفحه 4-2
فصل 8، “مدیر قفل توزیع شده یکپارچه: دسترسی به منابع”
Oracle8 Concepts برای اطلاعات بیشتر در مورد فرآیندهای پس زمینه DBWR، LGWR و LMD.
سیستم پایگاه داده توزیع شده
چندین سرور اوراکل و پایگاه داده را می توان برای تشکیل یک سیستم پایگاه داده توزیع شده پیوند داد. این پیکربندی شامل چندین پایگاه داده است که هر یک مستقیماً توسط یک سرور قابل دسترسی است و نمونه های دیگر از طریق همکاری سرور به سرور می توانند به طور غیر مستقیم به آنها دسترسی داشته باشند. هر گره را می توان برای پردازش پایگاه داده استفاده کرد، اما داده ها به طور دائم در بین گره ها تقسیم می شوند. در مقابل، یک سرور موازی دارای چندین نمونه است که دسترسی مستقیم به یک پایگاه داده را به اشتراک می گذارند.
توجه: سرور موازی Oracle می تواند یکی از اجزای تشکیل دهنده یک پایگاه داده توزیع شده باشد.
شکل 1-9 یک سیستم پایگاه داده توزیع شده را نشان می دهد. این سیستم پایگاه داده به فرآیند پس زمینه RECO در هر نمونه نیاز دارد. هیچ فرآیند پسزمینه LCK، LMON یا LMD وجود ندارد، زیرا این پیکربندی سرور موازی Oracle نیست و به مدیریت قفل توزیعشده مجتمع نیازی نیست.
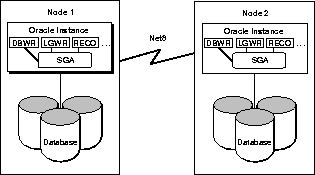
شکل 1-9 سیستم پایگاه داده توزیع شده
چندین پایگاه داده یک سیستم توزیع شده را می توان به عنوان یک پایگاه داده منطقی در نظر گرفت، زیرا سرورها می توانند با استفاده از Net8 به پایگاه داده های راه دور به طور شفاف دسترسی داشته باشند.
اگر دادههای شما را میتوان به چندین پایگاه داده با حداقل همپوشانی تقسیم کرد، میتوانید به جای سرور موازی از یک سیستم پایگاه داده توزیعشده استفاده کنید و دادهها را بین پایگاههای داده با Net8 به اشتراک بگذارید. یک سرور موازی اشتراک گذاری خودکار داده ها را در بین گره ها از طریق پایگاه داده مشترک فراهم می کند.
یک سیستم پایگاه داده توزیع شده به شما این امکان را می دهد که داده های خود را در چندین سایت کاملاً مجزا نگهداری کنید. تا زمانی که اتصالات شبکه بین گرههای جداگانه وجود داشته باشد، کاربران میتوانند از پایگاههای دادهای که از نظر جغرافیایی دور هستند، دسترسی داشته باشند. یک سرور موازی به دلیل نیاز به تأخیر کم و ارتباط با پهنای باند بالا بین گرهها، نیاز دارد که همه دادهها در یک سایت واحد باشند، اما میتواند بخشی از یک سیستم پایگاه داده توزیعشده نیز باشد. چنین سیستمی در شکل 1-10 نشان داده شده است.
شکل 1-10 سرور موازی Oracle به عنوان بخشی از یک پایگاه داده توزیع شده
پایگاه داده های متعدد نیاز به مدیریت پایگاه داده جداگانه دارند و یک سیستم پایگاه داده توزیع شده نیاز به مدیریت هماهنگ پایگاه های داده و پروتکل های شبکه دارد. یک سرور موازی می تواند چندین پایگاه داده را برای ساده سازی وظایف اداری یکپارچه کند.
پایگاههای اطلاعاتی چندگانه میتوانند دسترسی بیشتری نسبت به یک نمونه واحد که به یک پایگاه داده واحد دسترسی دارد، فراهم کنند، زیرا شکست نمونه در یک سیستم پایگاه داده توزیع شده مانع از دسترسی به دادهها در پایگاههای دیگر نمیشود: فقط پایگاه داده متعلق به نمونه ناموفق غیرقابل دسترسی است. با این حال، یک سرور موازی امکان دسترسی مداوم به تمام دادهها را در صورت خرابی یک نمونه، از جمله دادههایی که توسط نمونه در حال اجرا بر روی گره شکست خورده به آنها دسترسی پیدا کرده است، میدهد.
یک سرور موازی که به یک پایگاه داده تلفیقی دسترسی دارد، میتواند از نیاز به بهروزرسانیهای توزیع شده، درجها یا حذفها و ارتکابهای دو فازی گرانتر با اجازه دادن به تراکنش بر روی هر گره برای نوشتن همزمان در چندین جدول، صرف نظر از اینکه کدام گرهها معمولاً روی آن جداول مینویسند، اجتناب کند. .
همچنین برای اطلاعات کامل در مورد ویژگی های پایگاه داده توزیع شده Oracle به: Oracle8 Distributed Database Systems مراجعه کنید.
سیستم های کلاینت-سرور
هر یک از تنظیمات اوراکل می تواند در محیط سرویس گیرنده-سرور اجرا شود. در اوراکل، یک برنامه کلاینت بر روی یک کامپیوتر راه دور اجرا می شود و از Net8 برای دسترسی به سرور اوراکل از طریق شبکه استفاده می کند. عملکرد این پیکربندی معمولاً به قدرت گره سرور منفرد محدود می شود.
شکل 1-11 یک سیستم مشتری-سرور Oracle را نشان می دهد.
شکل 1-11 سیستم مشتری-سرور
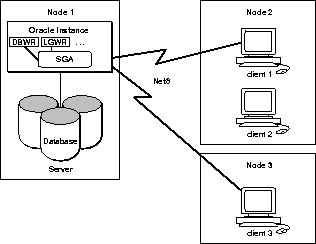
توجه: پردازش سرویس گیرنده-سرور برای هر پیکربندی Oracle مناسب است. اسناد مخصوص پلتفرم Oracle خود را بررسی کنید تا ببینید آیا در پلتفرم شما پیاده سازی شده است یا خیر.
پیکربندی سرویس گیرنده-سرور به شما اجازه می دهد تا پردازش را از رایانه ای که سرور اوراکل را اجرا می کند، بارگیری کنید. اگر برنامههای زیادی دارید که روی یک دستگاه اجرا میشوند، میتوانید برای بهبود عملکرد آنها را بارگذاری کنید. با این حال، اگر سرور پایگاه داده شما به محدودیت های پردازشی خود می رسد، ممکن است بخواهید به یک ماشین بزرگتر یا به یک سیستم چند گره بروید.
برای برنامههای محاسباتی فشرده، میتوانید برخی از برنامهها را در یک گره از یک سیستم چندگرهی در حالی که اوراکل را اجرا میکنید و سایر برنامهها را روی گره دیگری یا روی چندین گره دیگر اجرا کنید. به این ترتیب می توانید به طور موثر از گره های مختلف یک ماشین موازی به عنوان گره مشتری و یکی به عنوان گره سرور استفاده کنید.
اگر پایگاه داده متشکل از چندین بخش مجزا با توان عملیاتی بالا باشد، یک سرور موازی که بر روی گرههای با کارایی بالا اجرا میشود، میتواند پردازش سریعی را برای هر بخش از پایگاه داده ارائه دهد و در عین حال دسترسی گاه به گاه به بخشها را نیز مدیریت کند.
به یاد داشته باشید که پیکربندی مشتری-سرور مستلزم آن است که تمام ارتباطات بین برنامه مشتری و پایگاه داده از طریق شبکه انجام شود. این ممکن است در مواردی که حجم بسیار بالایی از چنین ارتباطاتی مورد نیاز است مناسب نباشد – مانند بسیاری از برنامه های دسته ای.
همچنین ببینید: “معماری مشتری-سرور” در Oracle8 Concepts
اجرای موازی چگونه جا می گیرد؟
با ویژگی های اجرای موازی خود، اوراکل می تواند کار پردازش انواع خاصی از عبارات SQL را بین چندین فرآیند سرور پرس و جو تقسیم کند.
Oracle Parallel Server چارچوبی را برای اجرای موازی برای کار بین گره ها فراهم می کند. ویژگی های اجرای موازی در اوراکل با یا بدون گزینه سرور موازی به همین صورت عمل می کنند. تنها تفاوت این است که OPS چندین گره را قادر می سازد تا از طرف یک پرس و جو یا سایر عملیات موازی اجرا شوند.
در برخی از برنامهها (بهویژه برنامههای ذخیرهسازی داده)، یک پرسوجوی فردی مقدار زیادی از منابع CPU و ورودی/خروجی دیسک را مصرف میکند، برخلاف اکثر تراکنشهای درج یا بهروزرسانی آنلاین. برای استفاده از سیستم های چند پردازشی، سرور داده باید پرس و جوهای فردی را در واحدهای کاری که می توانند به طور همزمان پردازش شوند موازی کند. شکل 1-12 نمونه ای از پردازش پرس و جو موازی را نشان می دهد.
شکل 1-12 نمونه ای از پردازش پرس و جو موازی
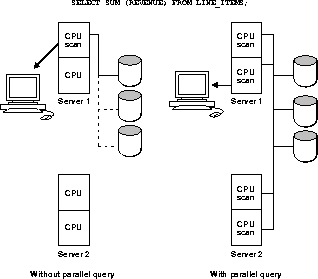
اگر پرس و جو به صورت موازی پردازش نمی شد، دیسک ها به صورت سریال با یک I/O خوانده می شدند. یک CPU منفرد باید همه ردیفهای جدول LINE_ITEMS را اسکن کند و درآمد را در همه ردیفها جمع کند. با موازی شدن پرس و جو، دیسک ها به صورت موازی و با چندین I/O خوانده می شوند. چندین CPU می توانند هر کدام بخشی از جدول را به صورت موازی اسکن کرده و نتایج را جمع آوری کنند. پرس و جوی موازی نه تنها از چندین CPU بلکه از پهنای باند ورودی/خروجی بیشتری نیز سود می برد.
همچنین برای بررسی دقیق اجرای موازی به: Oracle8 Concepts و Oracle8 Tuning مراجعه کنید.