")
پردازش موازی در پایتون python
پردازش موازی می تواند تعداد کارهای انجام شده توسط برنامه شما را افزایش دهد که زمان کلی پردازش را کاهش می دهد. اینها به حل مشکلات در مقیاس بزرگ کمک می کنند.
در این بخش به موضوعات زیر می پردازیم:
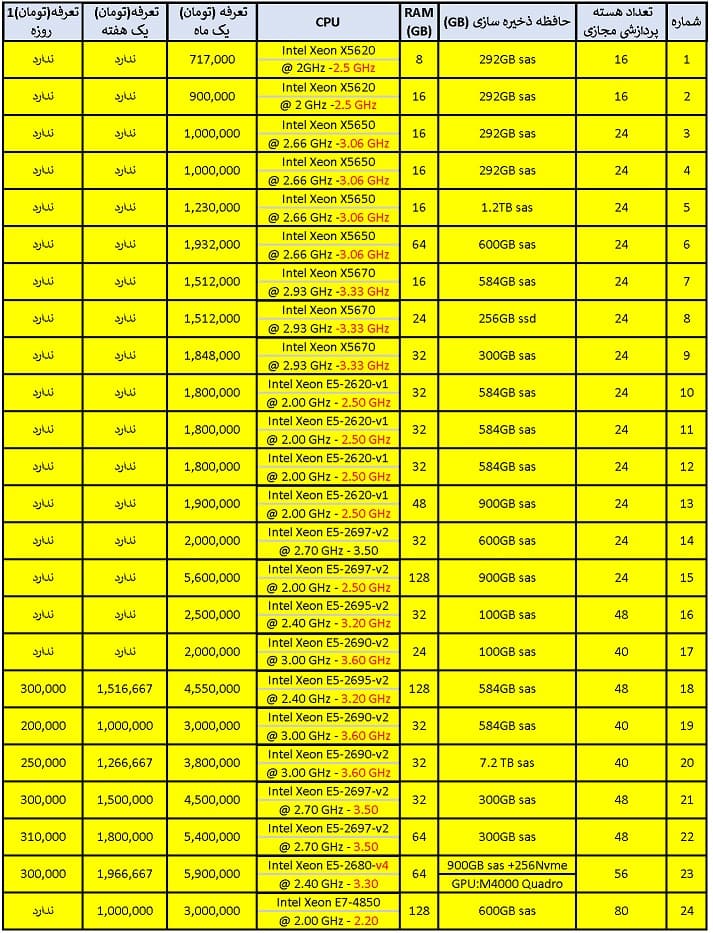
← اجاره ابر رایانه →
مقدمه ای بر پردازش موازی
کتابخانه Python Multi Processing برای پردازش موازی
چارچوب موازی IPython
مقدمه ای بر پردازش موازی
برای موازی سازی، مهم است که مسئله را به واحدهای فرعی تقسیم کنیم که به واحدهای فرعی دیگر (یا کمتر وابسته) وابسته نیستند. مشکلی که در آن واحدهای فرعی کاملاً مستقل از سایر واحدهای فرعی هستند، به طور شرم آور موازی نامیده می شود.
به عنوان مثال، عملیات یک عنصر بر روی یک آرایه. در این مورد، عملیات باید از عنصر خاصی که در حال حاضر با آن کار می کند آگاه باشد.
در سناریویی دیگر، یک مشکل که به واحدهای فرعی تقسیم می شود، باید برخی از داده ها را برای انجام عملیات به اشتراک بگذارد. این به دلیل هزینه ارتباطی منجر به مشکل عملکرد می شود.
دو روش اصلی برای مدیریت برنامه های موازی وجود دارد:
حافظه مشترک
در حافظه مشترک، واحدهای فرعی می توانند از طریق همان فضای حافظه با یکدیگر ارتباط برقرار کنند. مزیت این است که شما نیازی به مدیریت صریح ارتباط ندارید زیرا این روش برای خواندن یا نوشتن از حافظه مشترک کافی است. اما مشکل زمانی ایجاد می شود که چندین فرآیند به طور همزمان به یک حافظه دسترسی داشته باشند و مکان یکسانی را تغییر دهند. با استفاده از تکنیک های همگام سازی می توان از این تضاد جلوگیری کرد.
حافظه توزیع شده
در حافظه توزیع شده، هر فرآیند کاملاً از هم جدا شده و فضای حافظه خاص خود را دارد. در این سناریو، ارتباط به طور صریح بین فرآیندها انجام می شود. از آنجایی که ارتباط از طریق یک رابط شبکه انجام می شود، در مقایسه با حافظه مشترک هزینه بیشتری دارد.
نخ ها یکی از راه های رسیدن به موازی با حافظه مشترک هستند. اینها وظایف فرعی مستقلی هستند که از یک فرآیند سرچشمه می گیرند و حافظه را به اشتراک می گذارند. با توجه به Global Interpreter Lock (GIL)، نمی توان از رشته ها برای افزایش عملکرد در پایتون استفاده کرد. GIL مکانیزمی است که در آن طراحی مفسر پایتون اجازه می دهد تنها یک دستور پایتون در یک زمان اجرا شود. با استفاده از فرآیندها به جای نخ می توان از محدودیت GIL به طور کامل اجتناب کرد. استفاده از فرآیندها دارای معایب کمی مانند ارتباطات بین فرآیندی کمتر نسبت به حافظه مشترک است، اما انعطاف پذیرتر و واضح تر است.
پردازش چندگانه برای پردازش موازی
با استفاده از ماژول استاندارد چند پردازشی، میتوانیم با ایجاد فرآیندهای فرزند، وظایف ساده را موازی کنیم. این ماژول یک رابط کاربری آسان را ارائه می دهد و شامل مجموعه ای از ابزارهای کمکی برای رسیدگی به ارسال کار و همگام سازی است.
کلاس فرآیند و استخر
روند
با زیرکلاس بندی multiprocessing.process، می توانید فرآیندی ایجاد کنید که به طور مستقل اجرا شود. با گسترش متد __init__ می توانید منبع را مقداردهی اولیه کنید و با پیاده سازی متد Process.run() می توانید کد زیر فرآیند را بنویسید. در کد زیر، نحوه ایجاد فرآیندی را می بینیم که شناسه اختصاص داده شده را چاپ می کند:

برای ایجاد فرآیند، باید شی Process خود را مقداردهی اولیه کنیم و متد Process.start() را فراخوانی کنیم. در اینجا Process.start() یک فرآیند جدید ایجاد می کند و متد Process.run() را فراخوانی می کند.
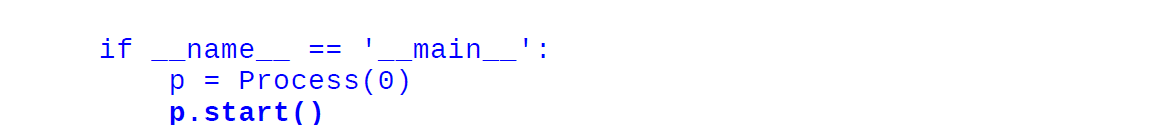
کد بعد از p.start() بلافاصله قبل از اتمام کار فرآیند p اجرا می شود. برای اینکه منتظر تکمیل کار باشید، می توانید از Process.join() استفاده کنید.

این کد کامل است:
import multiprocessing
import time
class Process(multiprocessing.Process):
def __init__(self, id):
super(Process, self).__init__()
self.id = id
def run(self):
time.sleep(1)
print(“I’m the process with id: {}”.format(self.id))
if __name__ == ‘__main__’:
p = Process(0)
p.start()
p.join()
p = Process(1)
p.start()
p.join()
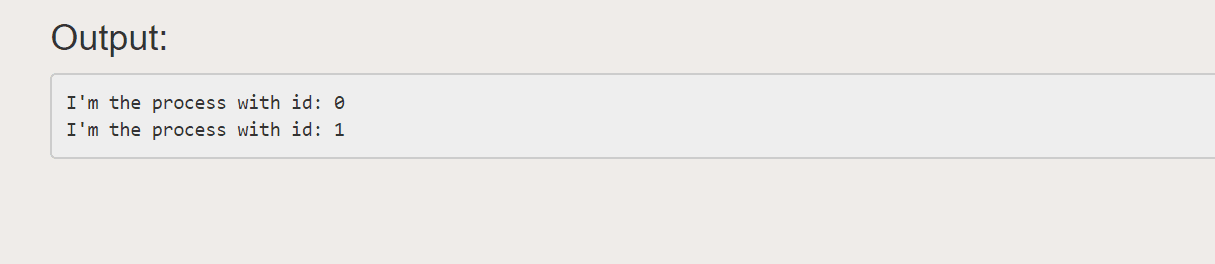
خروجی
کلاس استخر
کلاس Pool را می توان برای اجرای موازی یک تابع برای داده های ورودی مختلف استفاده کرد. کلاس multiprocessing.Pool () مجموعه ای از فرآیندها به نام کارگران را ایجاد می کند و می تواند وظایف را با استفاده از متدهای application/apply_async و map/map_async ارسال کند. برای نگاشت موازی، ابتدا باید یک شی ()multiprocessing.Pool را مقداردهی اولیه کنید. اولین استدلال تعداد کارگران است. اگر داده نشود، آن عدد برابر با تعداد هسته های سیستم خواهد بود.
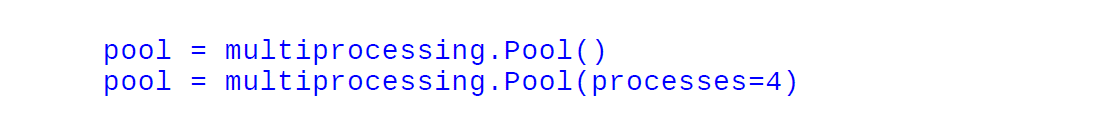
با یک مثال ببینیم در این مثال، نحوه ارسال تابعی را خواهیم دید که مربع یک عدد را محاسبه می کند. با استفاده از Pool.map () می توانید تابع را به لیست نگاشت کنید و تابع و لیست ورودی ها را به عنوان آرگومان ارسال کنید، به شرح زیر:

← مرکز محاسبات سریع شبیهسازان امیرکبیر →
import multiprocessing
import time
def square(x):
return x * x
if __name__ == ‘__main__’:
pool = multiprocessing.Pool()
pool = multiprocessing.Pool(processes=4)
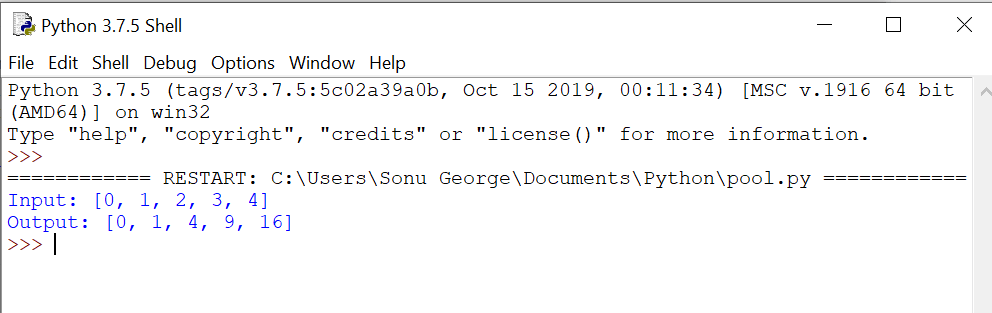
inputs = [0,1,2,3,4]
outputs = pool.map(square, inputs)
print(“Input: {}”.format(inputs))
print(“Output: {}”.format(outputs))
خروجی
وقتی از روش معمولی نقشه استفاده می کنیم، اجرای برنامه متوقف می شود تا زمانی که همه کارگران کار را انجام دهند. با استفاده از map_async()، شی AsyncResult بلافاصله بدون توقف برنامه اصلی برگردانده می شود و کار در پس زمینه انجام می شود. نتیجه را می توان با استفاده از متد AsyncResult.get در هر زمانی که در زیر نشان داده شده است بازیابی کرد:
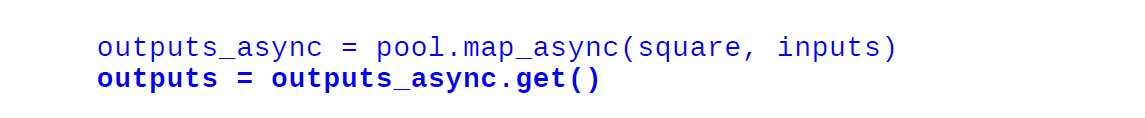
import multiprocessing
import time
def square(x):
return x * x
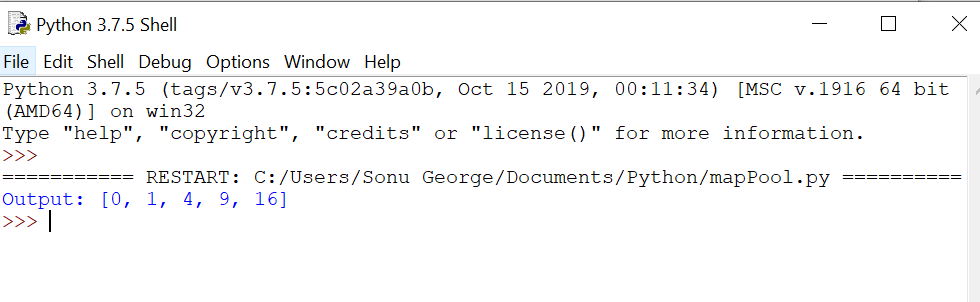
if __name__ == ‘__main__’:
pool = multiprocessing.Pool()
inputs = [0,1,2,3,4]
outputs_async = pool.map_async(square, inputs)
outputs = outputs_async.get()
print(“Output: {}”.format(outputs))
خروجی
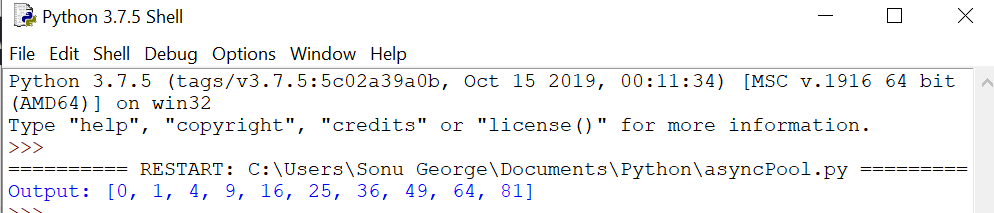
Pool.apply_async وظیفه ای متشکل از یک تابع را به یکی از کارگران اختصاص می دهد. تابع و آرگومان های آن را می گیرد و یک شی AsyncResult را برمی گرداند.

import multiprocessing
import time
def square(x):
return x * x
if __name__ == ‘__main__’:
pool = multiprocessing.Pool()
result_async = [pool.apply_async(square, args = (i, )) for i in
range(10)]
results = [r.get() for r in result_async]
print(“Output: {}”.format(results))
خروجی
چارچوب موازی IPython
بسته موازی IPython چارچوبی را برای تنظیم و اجرای یک کار بر روی ماشینهای تک هستهای و چندین گره متصل به شبکه فراهم میکند. در IPython.parallel، باید مجموعه ای از کارگران به نام Engines را راه اندازی کنید که توسط Controller مدیریت می شوند. کنترلر موجودی است که به برقراری ارتباط بین مشتری و موتور کمک می کند. در این رویکرد، فرآیندهای کارگر به طور جداگانه شروع می شوند و به طور نامحدود منتظر دستورات مشتری می مانند.
از دستورات پوسته Ipcluster برای راه اندازی کنترلر و موتورها استفاده می شود.
شروع ipcluster $
پس از فرآیند فوق، میتوانیم از یک پوسته IPython برای انجام موازی کار استفاده کنیم. IPython دارای دو رابط اصلی است:
رابط مستقیم
رابط مبتنی بر وظیفه
رابط مستقیم
رابط مستقیم به شما امکان می دهد دستورات را به طور صریح به هر یک از واحدهای محاسباتی ارسال کنید. این انعطاف پذیر و آسان برای استفاده است. برای تعامل با واحدها، باید موتور و سپس یک جلسه IPython در یک پوسته جداگانه راه اندازی کنید. می توانید با ایجاد یک کلاینت به کنترلر ارتباط برقرار کنید. در کد زیر، کلاس Client را وارد کرده و یک نمونه ایجاد می کنیم:
from IPython.parallel import Client
rc = Client()
rc.ids
در اینجا، Client.ids لیستی از اعداد صحیح را ارائه می دهد که جزئیات موتورهای موجود را ارائه می دهد.
با استفاده از نمونه Direct View، می توانید دستوراتی را به موتور صادر کنید. به دو روش می توانیم یک نمونه مشاهده مستقیم دریافت کنیم:
با نمایه سازی نمونه مشتری
dview = rc[0]
با فراخوانی متد DirectView.direct_view
dview = rc.direct_view (‘all’).
به عنوان آخرین مرحله، می توانید دستورات را با استفاده از روش DirectView.execute اجرا کنید.
dview.execute(‘ a = 1 ’)
دستور فوق به صورت جداگانه توسط هر موتور اجرا می شود. با استفاده از متد get می توانید نتیجه را در قالب یک شی AsyncResult دریافت کنید.
dview.pull(‘ a ‘).get()dview.push({‘ a ’ : 2})
همانطور که در بالا نشان داده شده است، می توانید با استفاده از روش DirectView.pull داده ها را بازیابی کنید و با استفاده از روش DirectView.push داده ها را ارسال کنید.
رابط مبتنی بر وظیفه
رابط مبتنی بر وظیفه روشی هوشمند برای انجام وظایف محاسباتی ارائه می دهد. از نظر کاربر، این رابط انعطافپذیری کمتری دارد، اما در متعادلسازی بار روی موتورها کارآمد است و میتواند کارهای ناموفق را دوباره ارسال کند و در نتیجه عملکرد را افزایش دهد.
کلاس LoadBalanceView رابط مبتنی بر وظیفه را با استفاده از روش load_balanced_view فراهم می کند.
from IPython.parallel import Client rc = Client() tview = rc.load_balanced_view()
با استفاده از روش نقشه و اعمال می توانیم برخی کارها را اجرا کنیم. در LoadBalanceView تخصیص کار بستگی به مقدار باری دارد که در آن زمان روی موتور وجود دارد. این تضمین می کند که همه موتورها بدون خرابی کار می کنند.
مطالب مرتبط:
← اجاره ابر رایانه →


