
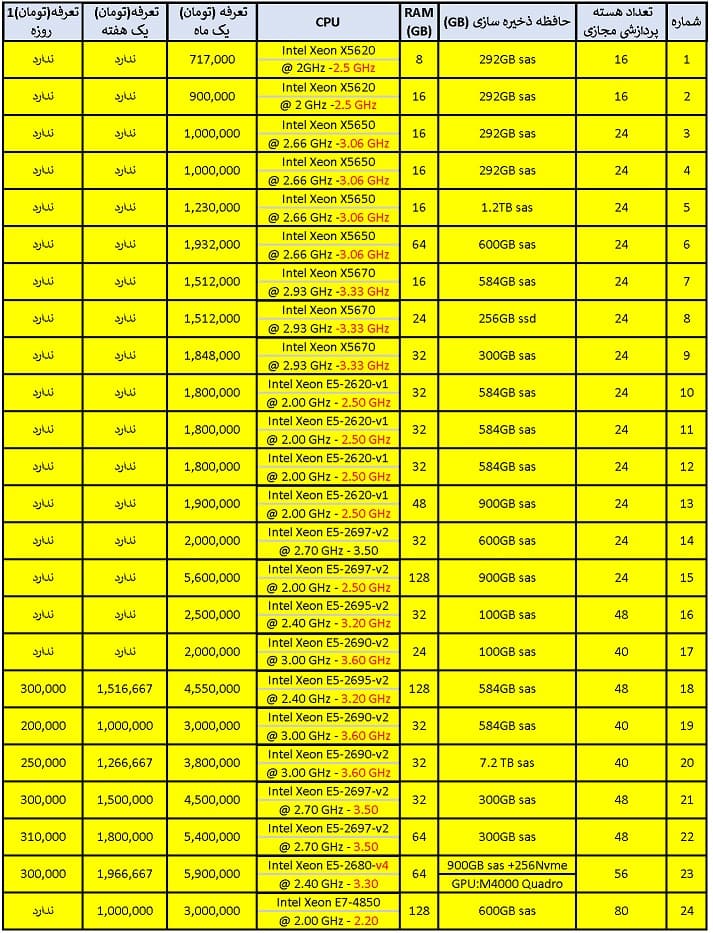
خوشه کامپیوتری
خوشه کامپیوتری مجموعه ای از رایانه ها است که با هم کار می کنند تا بتوان آنها را به عنوان یک سیستم واحد مشاهده کرد. بر خلاف کامپیوترهای شبکه ای، خوشه های کامپیوتری هر گره را برای انجام وظایف مشابه، کنترل و برنامه ریزی شده توسط نرم افزار تنظیم می کنند.
← اجاره ابر رایانه →
اجزای یک خوشه معمولاً از طریق شبکه های محلی سریع به یکدیگر متصل می شوند و هر گره (رایانه ای که به عنوان سرور استفاده می شود) نمونه خود را از یک سیستم عامل اجرا می کند. در بیشتر شرایط، همه گرهها از سختافزار یکسانی استفاده میکنند[1][منبع بهتر مورد نیاز] و سیستمعامل یکسان، اگرچه در برخی تنظیمات (مثلاً با استفاده از منابع برنامه Cluster Source (OSCAR))، سیستمعاملهای مختلف میتوانند در هر کامپیوتر یا سخت افزار مختلف.[2]
خوشه ها معمولاً برای بهبود عملکرد و در دسترس بودن نسبت به یک رایانه منفرد مستقر می شوند، در حالی که معمولاً نسبت به رایانه های منفرد با سرعت یا در دسترس بودن مشابه مقرون به صرفه تر هستند.[3]
خوشه های کامپیوتری در نتیجه همگرایی تعدادی از روندهای محاسباتی از جمله در دسترس بودن ریزپردازنده های کم هزینه، شبکه های پرسرعت و نرم افزار برای محاسبات پراکنده با کارایی بالا پدید آمدند. ، از خوشه های کسب و کار کوچک با تعداد انگشت شماری گره گرفته تا برخی از سریع ترین ابررایانه های جهان مانند سکویا IBM.[4] قبل از ظهور خوشهها، از مینفریمهای تک واحدی مقاوم به خطا با افزونگی مدولار استفاده میشد. اما هزینه اولیه پایین تر خوشه ها و افزایش سرعت بافت شبکه باعث پذیرش خوشه ها شده است. برخلاف پردازندههای مرکزی با قابلیت اطمینان بالا، دستهبندیها ارزانتر هستند، اما همچنین پیچیدگی بیشتری در رسیدگی به خطا دارند، زیرا در خوشهها، حالتهای خطا برای اجرای برنامهها غیرشفاف نیستند.


میل به دستیابی به قدرت محاسباتی بیشتر و قابلیت اطمینان بهتر با هماهنگی تعدادی از کامپیوترهای تجاری ارزان قیمت، باعث ایجاد انواع معماری و پیکربندی شده است.
رویکرد خوشهبندی رایانه معمولاً (اما نه همیشه) تعدادی از گرههای محاسباتی در دسترس (مانند رایانههای شخصی که به عنوان سرور استفاده میشوند) را از طریق یک شبکه محلی سریع به هم متصل میکند.[6] فعالیتهای گرههای محاسباتی توسط «میانافزار خوشهبندی» تنظیم میشوند، یک لایه نرمافزاری که در بالای گرهها قرار میگیرد و به کاربران اجازه میدهد تا خوشه را بهعنوان یک واحد محاسباتی منسجم در نظر بگیرند، مثلاً. از طریق یک مفهوم تصویر سیستم واحد.[6]
خوشه بندی کامپیوتری بر یک رویکرد مدیریت متمرکز متکی است که گره ها را به عنوان سرورهای مشترک هماهنگ شده در دسترس قرار می دهد. از دیگر رویکردها مانند محاسبات همتا به همتا یا شبکه که از گرههای زیادی نیز استفاده میکنند، اما با ماهیت بسیار توزیعشدهتری متمایز است.[6]
یک خوشه کامپیوتری ممکن است یک سیستم دو گره ساده باشد که فقط دو کامپیوتر شخصی را به هم متصل می کند، یا ممکن است یک ابر کامپیوتر بسیار سریع باشد. یک رویکرد اساسی برای ساخت یک خوشه، رویکرد یک خوشه Beowulf است که ممکن است با چند رایانه شخصی ساخته شود تا جایگزینی مقرون به صرفه برای محاسبات با کارایی بالا سنتی تولید کند. یک پروژه اولیه که قابلیت این مفهوم را نشان داد، سوپرکامپیوتر سنگی 133 گره بود.[7] توسعه دهندگان از لینوکس، جعبه ابزار ماشین مجازی موازی و کتابخانه رابط ارسال پیام برای دستیابی به عملکرد بالا با هزینه نسبتا کم استفاده کردند.[8]
اگرچه یک خوشه ممکن است فقط از چند کامپیوتر شخصی تشکیل شده باشد که توسط یک شبکه ساده به هم متصل شده اند، معماری خوشه ممکن است برای دستیابی به سطوح بسیار بالایی از عملکرد نیز استفاده شود. لیست شش ماهه سازمان TOP500 از 500 سریعترین ابررایانه اغلب شامل خوشه های زیادی می شود، به عنوان مثال. سریع ترین ماشین جهان در سال 2011 کامپیوتر K بود که دارای حافظه توزیع شده، معماری خوشه ای است.[9]

Greg Pfister بیان کرده است که خوشهها توسط هیچ فروشنده خاصی اختراع نشدهاند، بلکه توسط مشتریانی اختراع شدهاند که نمیتوانند تمام کارهای خود را روی یک رایانه جا دهند، یا نیاز به یک نسخه پشتیبان دارند.[10] Pfister تاریخ را در دهه 1960 تخمین می زند. اساس مهندسی رسمی محاسبات خوشهای بهعنوان وسیلهای برای انجام کارهای موازی از هر نوع، احتمالاً توسط Gene Amdahl از IBM ابداع شد، که در سال 1967 آنچه را که به عنوان مقاله اصلی در مورد پردازش موازی در نظر گرفته میشود منتشر کرد: قانون Amdahl.
تاریخچه خوشه های کامپیوتری اولیه کم و بیش مستقیماً با تاریخچه شبکه های اولیه گره خورده است، زیرا یکی از انگیزه های اولیه برای توسعه یک شبکه، پیوند دادن منابع محاسباتی، ایجاد یک خوشه کامپیوتری بالفعل بود.
اولین سیستم تولیدی که به صورت خوشه ای طراحی شد، باروز B5700 در اواسط دهه 1960 بود. این اجازه میدهد تا چهار کامپیوتر، هر کدام با یک یا دو پردازنده، بهمنظور توزیع حجم کار، بهطور محکم به یک زیرسیستم ذخیرهسازی دیسک مشترک متصل شوند. برخلاف سیستمهای چند پردازندهای استاندارد، هر رایانه میتواند بدون ایجاد اختلال در عملکرد کلی، راهاندازی مجدد شود.
اولین محصول تجاری خوشهبندی آزاد، سیستم «رایانه منبع پیوست» (ARC) شرکت Datapoint بود که در سال 1977 توسعه یافت و از ARCnet به عنوان رابط خوشهای استفاده کرد. خوشهبندی فینفسه تا زمانی که Digital Equipment Corporation محصول VAXcluster خود را در سال 1984 برای سیستمعامل VMS منتشر کرد، واقعاً مطرح نشد. محصولات ARC و VAXcluster نه تنها از محاسبات موازی پشتیبانی میکنند، بلکه سیستمهای فایل مشترک و دستگاههای جانبی را نیز پشتیبانی میکنند. ایده این بود که مزایای پردازش موازی، در عین حفظ قابلیت اطمینان و منحصر به فرد بودن داده ها، فراهم شود. دو خوشه تجاری اولیه قابل توجه دیگر Tandem Himalayan (یک محصول در دسترس در حدود 1994) و IBM S/390 Parallel Sysplex (همچنین در حدود سال 1994، عمدتاً برای استفاده تجاری) بودند.
در همان چارچوب زمانی، در حالی که خوشه های کامپیوتری از موازی سازی خارج از کامپیوتر در یک شبکه کالایی استفاده می کردند، ابررایانه ها شروع به استفاده از آنها در همان کامپیوتر کردند. پس از موفقیت CDC 6600 در سال 1964، Cray 1 در سال 1976 ارائه شد و موازی سازی داخلی از طریق پردازش برداری معرفی شد.[11] در حالی که ابررایانههای اولیه خوشهها را حذف میکردند و به حافظه مشترک تکیه میکردند، با گذشت زمان برخی از سریعترین ابررایانهها (مانند رایانه K) به معماریهای خوشهای متکی بودند.
خوشه های کامپیوتری ممکن است برای اهداف مختلفی از نیازهای تجاری با اهداف عمومی مانند پشتیبانی از خدمات وب تا محاسبات علمی محاسباتی فشرده پیکربندی شوند. در هر صورت، خوشه ممکن است از رویکرد دسترسی بالا استفاده کند. توجه داشته باشید که ویژگی های شرح داده شده در زیر انحصاری نیستند و یک “خوشه کامپیوتری” نیز ممکن است از رویکرد دسترسی بالا و غیره استفاده کند.
← مرکز محاسبات سریع شبیهسازان امیرکبیر →
خوشههای «تعادل بار» پیکربندیهایی هستند که در آنها، گرههای خوشه بار محاسباتی را برای ارائه عملکرد کلی بهتر به اشتراک میگذارند. به عنوان مثال، یک خوشه وب سرور ممکن است پرس و جوهای مختلفی را به گره های مختلف اختصاص دهد، بنابراین زمان پاسخ کلی بهینه خواهد شد.[12] با این حال، رویکردهای تعادل بار ممکن است به طور قابل توجهی در بین برنامه ها متفاوت باشد، به عنوان مثال. یک خوشه با کارایی بالا که برای محاسبات علمی استفاده میشود، بار را با الگوریتمهای مختلف از یک خوشه وب سرور متعادل میکند که ممکن است با اختصاص دادن هر درخواست جدید به یک گره متفاوت، از یک روش دور ساده استفاده کند.[12]
خوشه های کامپیوتری برای اهداف محاسباتی فشرده، به جای مدیریت عملیات IO-گرا مانند وب سرویس یا پایگاه داده استفاده می شوند.[13] به عنوان مثال، یک خوشه کامپیوتری ممکن است از شبیه سازی محاسباتی تصادفات خودرو یا آب و هوا پشتیبانی کند. خوشه های کامپیوتری بسیار محکم برای کارهایی طراحی شده اند که ممکن است به “ابر محاسبات” نزدیک شوند.
«خوشههای با دسترسی بالا» (همچنین به عنوان خوشههای شکست خورده یا خوشههای HA شناخته میشوند) در دسترس بودن رویکرد خوشهای را بهبود میبخشند. آنها با داشتن گره های اضافی کار می کنند، که سپس برای ارائه خدمات در صورت خرابی اجزای سیستم استفاده می شوند. پیاده سازی خوشه HA سعی می کند از افزونگی اجزای خوشه برای حذف نقاط شکست استفاده کند. برای بسیاری از سیستم عامل ها، پیاده سازی های تجاری از خوشه های دسترسی بالا وجود دارد. پروژه Linux-HA یکی از بسته های نرم افزار رایگان HA است که معمولا برای سیستم عامل لینوکس استفاده می شود.
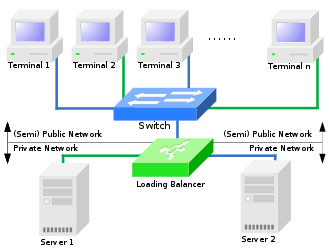
خوشه ها در درجه اول با در نظر گرفتن عملکرد طراحی می شوند، اما نصب بر اساس بسیاری از عوامل دیگر است. تحمل خطا (توانایی یک سیستم برای ادامه کار با یک گره خراب) امکان مقیاس پذیری و در موقعیت های با کارایی بالا، فرکانس پایین روال نگهداری، تلفیق منابع (مانند RAID) و مدیریت متمرکز را فراهم می کند. مزایا عبارتند از فعال کردن بازیابی اطلاعات در صورت وقوع فاجعه و ارائه پردازش موازی داده و ظرفیت پردازش بالا.[14][15]
از نظر مقیاس پذیری، خوشه ها این را در توانایی خود برای اضافه کردن گره ها به صورت افقی فراهم می کنند. این بدان معنی است که ممکن است رایانه های بیشتری به خوشه اضافه شود تا عملکرد، افزونگی و تحمل خطا را بهبود بخشد. این می تواند یک راه حل ارزان قیمت برای یک خوشه با عملکرد بالاتر در مقایسه با افزایش مقیاس یک گره در خوشه باشد. این ویژگی از خوشه های کامپیوتری می تواند اجازه دهد تا بارهای محاسباتی بزرگتر توسط تعداد بیشتری از رایانه های با عملکرد پایین تر اجرا شوند.
هنگام افزودن یک گره جدید به یک خوشه، قابلیت اطمینان افزایش می یابد زیرا نیازی به حذف کل خوشه نیست. یک گره منفرد را می توان برای نگهداری از بین برد، در حالی که بقیه خوشه بار آن گره منفرد را بر عهده می گیرد.
اگر تعداد زیادی کامپیوتر را در کنار هم قرار دهید، این خود به استفاده از سیستم های فایل توزیع شده و RAID کمک می کند، که هر دو می توانند قابلیت اطمینان و سرعت یک خوشه را افزایش دهند.
یکی از مسائلی که در طراحی یک خوشه وجود دارد این است که گرههای مجزا چقدر به هم متصل هستند. به عنوان مثال، یک کار کامپیوتری ممکن است نیاز به ارتباط مکرر بین گره ها داشته باشد: این نشان می دهد که خوشه یک شبکه اختصاصی را به اشتراک می گذارد، به طور متراکم قرار دارد و احتمالاً دارای گره های همگن است. حالت افراطی دیگر جایی است که یک کار کامپیوتری از یک یا چند گره استفاده می کند و به ارتباطات بین گره ای کم یا بدون نیاز است و به محاسبات شبکه نزدیک می شود.
در یک خوشه Beowulf، برنامههای کاربردی هرگز گرههای محاسباتی (همچنین رایانههای برده نامیده میشوند) را نمیبینند، بلکه فقط با «Master» که رایانهای خاص است که زمانبندی و مدیریت بردگان را مدیریت میکند، تعامل دارند.[13] در یک پیاده سازی معمولی، Master دارای دو رابط شبکه است، یکی که با شبکه خصوصی Beowulf برای بردگان ارتباط برقرار می کند، و دیگری برای شبکه هدف عمومی سازمان.[13] کامپیوترهای برده معمولاً نسخه خود را از همان سیستم عامل و حافظه محلی و فضای دیسک دارند. با این حال، شبکه برده خصوصی ممکن است یک سرور فایل بزرگ و مشترک نیز داشته باشد که دادههای دائمی جهانی را ذخیره میکند و بردهها در صورت نیاز به آن دسترسی دارند.[13]
یک خوشه 144 گره ای DEGIMA با هدف ویژه برای اجرای شبیه سازی های اخترفیزیکی N-body با استفاده از کد درختی موازی Multiple-Walk به جای محاسبات علمی با هدف عمومی تنظیم شده است.[16]
با توجه به افزایش قدرت محاسباتی هر نسل از کنسولهای بازی، کاربرد جدیدی پدید آمده است که در آن به کلاسترهای محاسباتی با کارایی بالا (HPC) تبدیل میشوند. برخی از نمونههای خوشههای کنسول بازی، دستههای پلیاستیشن سونی و کلاسترهای ایکسباکس مایکروسافت هستند. نمونه دیگری از محصولات بازی های مصرفی، ایستگاه کاری سوپرکامپیوتر شخصی انویدیا تسلا است که از چندین تراشه پردازشگر شتاب دهنده گرافیکی استفاده می کند. علاوه بر کنسولهای بازی، میتوان از کارتهای گرافیکی سطح بالا نیز استفاده کرد. استفاده از کارتهای گرافیک (یا بهتر بگوییم GPU آنها) برای انجام محاسبات برای محاسبات شبکه، علیرغم دقت کمتر، بسیار مقرون به صرفهتر از استفاده از CPU است. با این حال، هنگام استفاده از مقادیر با دقت مضاعف، کار کردن با آنها به اندازه CPU ها دقیق می شود و هنوز هم هزینه کمتری دارند (هزینه خرید).[2]
خوشه های کامپیوتری در طول تاریخ بر روی کامپیوترهای فیزیکی جداگانه با سیستم عامل یکسان اجرا شده اند. با ظهور مجازیسازی، گرههای خوشه ممکن است روی رایانههای فیزیکی جداگانه با سیستمعاملهای مختلف اجرا شوند که در بالا با یک لایه مجازی نقاشی شدهاند تا شبیه به هم به نظر برسند. تنظیمات به عنوان تعمیر و نگهداری انجام می شود. یک مثال پیاده سازی Xen به عنوان مدیر مجازی سازی با Linux-HA است.[17]
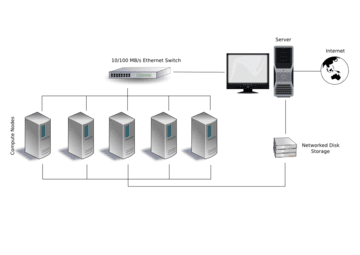
به اشتراک گذاری داده ها
همانطور که خوشه های کامپیوتری در دهه 1980 ظاهر شدند، ابررایانه ها نیز ظاهر شدند. یکی از عناصری که در آن زمان این سه کلاس را متمایز می کرد این بود که ابررایانه های اولیه بر حافظه مشترک متکی بودند. تا به امروز، خوشهها معمولاً از حافظه مشترک فیزیکی استفاده نمیکنند، در حالی که بسیاری از معماریهای ابر رایانه نیز آن را رها کردهاند.
با این حال، استفاده از یک سیستم فایل خوشهای در خوشههای رایانهای مدرن ضروری است.[نیازمند منبع] به عنوان مثال میتوان به سیستم فایل موازی عمومی IBM، حجمهای مشترک کلاستر مایکروسافت یا سیستم فایل اوراکل کلاستر اشاره کرد.
ارسال پیام و ارتباط
دو رویکرد پرکاربرد برای ارتباط بین گرههای خوشهای MPI (واسط عبور پیام) و PVM (ماشین مجازی موازی) هستند.[18]
PVM در آزمایشگاه ملی Oak Ridge در حدود سال 1989 قبل از در دسترس بودن MPI توسعه یافت. PVM باید مستقیماً روی هر گره خوشهای نصب شود و مجموعهای از کتابخانههای نرمافزاری را فراهم میکند که گره را به عنوان یک “ماشین مجازی موازی” رنگ میکند. PVM یک محیط زمان اجرا برای ارسال پیام، مدیریت کار و منابع و اطلاع رسانی خطا فراهم می کند. PVM می تواند توسط برنامه های کاربر نوشته شده در C، C++، یا Fortran و غیره استفاده شود.[18][19]
MPI در اوایل دهه 1990 از بحث و گفتگو بین 40 سازمان پدیدار شد. تلاش اولیه توسط ARPA و بنیاد ملی علوم پشتیبانی شد. طراحی MPI به جای شروع دوباره، از ویژگی های مختلف موجود در سیستم های تجاری آن زمان استفاده کرد. سپس مشخصات MPI منجر به پیاده سازی های خاصی شد. پیاده سازی های MPI معمولاً از اتصالات TCP/IP و سوکت استفاده می کنند.[18] MPI در حال حاضر یک مدل ارتباطی در دسترس است که برنامههای موازی را قادر میسازد به زبانهایی مانند C، Fortran، Python و غیره نوشته شوند.[19] بنابراین، بر خلاف PVM که یک پیاده سازی مشخص را ارائه می دهد، MPI مشخصاتی است که در سیستم هایی مانند MPICH و Open MPI پیاده سازی شده است.[19][20]

یکی از چالشهای استفاده از یک خوشه کامپیوتری، هزینه مدیریت آن است که در مواقعی میتواند به اندازه هزینه مدیریت N ماشین مستقل باشد، اگر خوشه N گره داشته باشد.[21] در برخی موارد این مزیتی را برای معماری حافظه مشترک با هزینههای مدیریت کمتر فراهم میکند.[21] این امر نیز به دلیل سهولت مدیریت باعث محبوبیت ماشین های مجازی شده است.[21]
زمان بندی کار
هنگامی که یک خوشه چند کاربر بزرگ نیاز به دسترسی به مقادیر بسیار زیادی از داده ها دارد، زمان بندی کار به یک چالش تبدیل می شود. در یک خوشه CPU-GPU ناهمگن با یک محیط کاربردی پیچیده، عملکرد هر کار به ویژگی های خوشه زیربنایی بستگی دارد. بنابراین، نگاشت وظایف بر روی هستههای CPU و دستگاههای GPU چالشهای مهمی را فراهم میکند.[22] این یک حوزه تحقیقاتی در حال انجام است. الگوریتمهایی که MapReduce و Hadoop را ترکیب و گسترش میدهند، پیشنهاد و مطالعه شدهاند.[22]
مدیریت خرابی گره
هنگامی که یک گره در یک خوشه از کار می افتد، استراتژی هایی مانند “حصاربندی” ممکن است برای عملیاتی نگه داشتن بقیه سیستم به کار گرفته شود.[23][24] حصاربندی فرآیند جداسازی یک گره یا محافظت از منابع مشترک زمانی است که به نظر می رسد یک گره در حال کار نکردن است. دو دسته از روش های حصارکشی وجود دارد. یکی خود گره را غیرفعال می کند و دیگری دسترسی به منابعی مانند دیسک های مشترک را ممنوع می کند.[23]
متد STONITH مخفف “Shoot The Other Node In The Head” است، به این معنی که گره مشکوک غیرفعال یا خاموش است. به عنوان مثال، حصار قدرت از یک کنترل کننده قدرت برای خاموش کردن یک گره غیرقابل استفاده استفاده می کند.[23]
رویکرد حصار منابع، دسترسی به منابع را بدون خاموش کردن گره مجاز نمیداند. این ممکن است شامل حصار رزرو مداوم از طریق SCSI3، حصار کانال فیبر برای غیرفعال کردن درگاه کانال فیبر، یا حصار دستگاه بلوک شبکه جهانی (GNBD) برای غیرفعال کردن دسترسی به سرور GNBD باشد.
توسعه و مدیریت نرم افزار
برنامه نویسی موازی
خوشه های متعادل کننده بار مانند وب سرورها از معماری های خوشه ای برای پشتیبانی از تعداد زیادی کاربر استفاده می کنند و معمولاً هر درخواست کاربر به یک گره خاص هدایت می شود و با توجه به اینکه هدف اصلی سیستم ارائه سریع کاربر است، موازی کاری بدون همکاری چند گره به دست می آید. دسترسی به داده های مشترک با این حال، «خوشههای رایانهای» که محاسبات پیچیده را برای تعداد کمی از کاربران انجام میدهند، باید از قابلیتهای پردازش موازی خوشه استفاده کنند و «محاسبات یکسان» را در میان چندین گره تقسیم کنند.[25]
موازی سازی خودکار برنامه ها همچنان یک چالش فنی است، اما مدل های برنامه نویسی موازی را می توان برای ایجاد درجه بالاتری از موازی سازی از طریق اجرای همزمان بخش های جداگانه یک برنامه در پردازنده های مختلف استفاده کرد.[25][26]
اشکال زدایی و نظارت
توسعه و اشکال زدایی برنامه های موازی در یک خوشه به زبان های ابتدایی موازی و ابزارهای مناسبی مانند مواردی که توسط انجمن اشکال زدایی با عملکرد بالا (HPDF) مورد بحث قرار گرفته است، نیاز دارد که منجر به مشخصات HPD شد.[19][27] سپس ابزارهایی مانند TotalView برای اشکالزدایی پیادهسازیهای موازی در خوشههای رایانهای که از رابط ارسال پیام (MPI) یا ماشین مجازی موازی (PVM) برای ارسال پیام استفاده میکنند، توسعه یافت.
سیستم شبکه ایستگاه های کاری دانشگاه کالیفرنیا، برکلی (NOW) داده های خوشه ای را جمع آوری می کند و آنها را در یک پایگاه داده ذخیره می کند، در حالی که سیستمی مانند PARMON که در هند توسعه یافته است، امکان مشاهده و مدیریت بصری خوشه های بزرگ را فراهم می کند.[19]
هنگامی که یک گره در طول یک محاسبه چند گره طولانی از کار می افتد، می توان از چک پوینت برنامه برای بازیابی وضعیت معینی از سیستم استفاده کرد.[28] این در خوشه های بزرگ ضروری است، با توجه به اینکه با افزایش تعداد گره ها، احتمال شکست گره تحت بارهای محاسباتی سنگین نیز افزایش می یابد. Checkpointing می تواند سیستم را به حالت پایدار بازگرداند تا پردازش بدون نیاز به محاسبه مجدد نتایج از سر گرفته شود.[28]
پیاده سازی ها
دنیای لینوکس از نرم افزارهای مختلف خوشه ای پشتیبانی می کند. برای خوشه بندی برنامه، distcc و MPICH وجود دارد. سرور مجازی لینوکس، Linux-HA – خوشههای مبتنی بر کارگردان که اجازه میدهند درخواستهای دریافتی برای سرویسها در چندین گره خوشه توزیع شوند. MOSIX، LinuxPMI، Kerrighed، OpenSSI خوشههای تمام عیار هستند که در هسته یکپارچه شدهاند که مهاجرت خودکار فرآیند را در میان گرههای همگن فراهم میکنند. OpenSSI، openMosix و Kerrighed پیاده سازی های تصویری تک سیستمی هستند.
Microsoft Windows Cluster Server 2003 مبتنی بر پلتفرم Windows Server قطعاتی را برای محاسبات با عملکرد بالا مانند Job Scheduler، کتابخانه MSMPI و ابزارهای مدیریتی ارائه می دهد.
gLite مجموعه ای از فناوری های میان افزاری است که توسط پروژه Enabling Grids for E-Science (EGEE) ایجاد شده است.
slurm همچنین برای برنامهریزی و مدیریت برخی از بزرگترین خوشههای ابررایانه استفاده میشود (به فهرست top500 مراجعه کنید).
رویکردهای دیگر
اگرچه اکثر خوشه های کامپیوتری وسایل ثابت هستند، تلاش هایی برای محاسبات فلش موب برای ایجاد خوشه های کوتاه مدت برای محاسبات خاص انجام شده است. با این حال، سیستم های محاسباتی داوطلبانه در مقیاس بزرگتر مانند سیستم های مبتنی بر BOINC پیروان بیشتری داشته اند.
: مطالب مرتبط
← اجاره ابر رایانه →


